Tik-76.115 Toiminnallinen määrittely
Cluster
http://www.hut.fi/~pemakela/ot/documents/to.html
Viimeksi päivitetty 22.3. 1998.
Sisällysluettelo
Yhteenveto
1. Johdanto
2. Yleiskuvaus
3. Tiedot ja tietokannat
4. Toiminnot
5. Ulkoiset liittymät
6. Muut ominaisuudet
Yhteenveto
-
Projekti
-
Kyseessä olevan projektin tarkoituksena on laatia ohjelmisto, joka
lukee www-palvelimen lokitietoja sekä tiedot www-palvelun rakenteesta
ja muodostaa näistä tiedoista käyttäjäklustereita,
ts. jakaa www-palvelimella käyneet käyttäjät erilaisiin
ryhmiin perustuen siihen mitä, milloin, missä järjestyksessä
jne. käyttäjät ovat palvelimelta hakeneet. Palvelimen käyttäjätietojen
rajauksessa sekä saatujen klustereiden jälkitarkastelussa voidaan
käyttää hyväksi niitä henkilötietoja, jotka
käyttäjät ovat itsestään antaneet rekisteröityessään
palvelun käyttäjiksi. Ohjelmiston kehityksessä käytetään
esimerkkipalvelimena Kauppalehti Online-palvelua,
sen www-palvelimen lokitietoja sekä käyttäjätietokantaa.
-
Tämä dokumentti
-
Tämä dokumentti, toiminnallinen määrittely, on tarkennettu
versio vaatimusmäärittelystä ja tämän
dokumentin tarkoituksena on tarkentaa asiakkaan vaatimukset ja toiveet
sekä rajata ja määritellä mahdollisista ominaisuuksista
ne mitä toteutetaan sekä miten ne toteutetaan. Dokumentissa esitellään
ohjelma pääpiirteittäin, sen liittymät, käyttöympäristö,
käyttäjät jne., kuvataan ohjelmiston sisältämien
tietokantojen sisällöt, ylimmän tason tietovirtakaaviot
sekä määritellään ohjelmistoon kuuluvat toiminnot.
-
Ohjelmiston yleiskuvaus
-
Ohjelmisto jakautuu ylimmällä tasolla kolmeen loogiseen moduliin:
tiedon esiprosessointiin, analyysiin sakä jälkitarkasteluun.
Esiprosessointi käsittää klusteroitavan aineiston rajauksen
sekä varsinaisen klusteroinnin konfiguroimisen ennen varsinaista analyysivaihetta,
jossa saaduista tiedoista muodostetaan klustereita. Jälkitarkasteluvaiheessa
saadut klusteritiedot tallennetaan jatkotarkastelua ja -käyttöä
varten, tuloksia voidaan visualisoida ja niiden perusteella voidaan ruveta
suorittamaan uutta analyysia joko tyhjästä tai sitten edellisen
analyysin tuloksista tarkentamalla.
-
Ohjelmisto kaavailtiin aluksi tehtäväksi C++:lla sekä Javalla
siten, että varsinainen klusterointi sekä tietokantojen hallinta
koodattaisiin C++:lla ja käyttöliittymä Javalla. Pian kuitenkin
huomattiin Javan tarjoavan käytännöllisä työkaluja
palvelimen (joka on yhteydessä tietokantoihin) sekä käyttöliittymäclientin
väliseen liikenteeseen sekä myös erittäin käyttökelpoisen
rajapinnan (JDBC) tietokantojen käsittelyyn ohjelmakoodista käsin.
Niinpä ohjelmisto päätettiin toteuttaa kokonaisuudessaan
Javalla. Ohjelmmiston tulee toimia sekä Windows NT-että Unix-ympäristöissä,
minkä ei pitäisi aiheuttaa Java-toteutuksella ongelmia. Ohjelmiston
ensisijaisia käyttäjiä ovat www-palvelimien ylläpitäjät
ja palveluntarjoajat.
-
Liittymät
-
Ohjelmisto lukee www-palvelimen rakenteen erillisestä tiedostosta
ja lokitiedot www-palvelimen tuottamasta tekstimuotoisesta lokista. Tämä
loki muunnetaan myös tietokannaksi käsittelyn helpottamiseksi.
Käyttäjätiedot ovat jo valmiiksi Oracle-kannassa.
-
Toiminnot
-
Toiminnot on jaettu kolmeen ryhmään: varsinaiseen klusterointiin
liittyvät toiminnot, tallennukseen liittyvät toiminnot sekä
visualisointiin liittyvät toiminnot. Toiminnot on selvitetty tarkemmin
luvussa 4.
-
Käyttöliittymä
-
Käyttöliittymä on jaettu käyttäjän kannalta
katsottuna kolmeen loogisen kokonaisuuteen: klusterointi ja siihen liittyvät
konfigurointi- ym. toimenpiteet, tulosten visualisointi sekä tulosten
hallinta, joka käsittää mahdollisuuden tallentaa, ladata
ja vertailla eri aikoina tehtyjä klusterointianalyyseja.
1. Johdanto
-
Tavoitteet
-
Projektin tarkoituksena on laatia ohjelmisto, joka saamiensa www-palvelimen
lokitietojen pohjalta klusteroi käyttäjiä eli jaottelee
käyttäjät erilaisiin ryhmiin sen mukaan mitä he ovat
www-palvelimelta hakeneet. Näin saatuja tietoja käyttäjien
klusteroitumisesta on tarkoitus käyttää mm. palvelimen sisällön
kehittämiseen, markkinointiin jne. Projektilla on kaksikin asiakasta;
TKK/TAI:n SmartPush-projekti sekä Aamulehtiyhtymä, varsinaisesti
tässä vaiheessa Kauppalehti
Online, joka tarjoaa projektin käyttöön www-palvelimensa
lokitiedot. SmartPushin, jonka osaksi tätä projektia kaavaillaan,
lopullinen tavoite on kyetä tarjoamaan käyttäjille vinkkejä
uusista heitä kiinnostavista aiheista sen perusteella, millaista tietoa
he ovat tähän mennessä hakeneet ja mitä muut samoista
asioista kiinnostuneet ovat lukeneet. Kauppalehden tavoitteena on paitsi
seurannan kautta kehittää palvelimensa laatua ja kiinnostavuutta
myös käyttää saatuja tietoja mediamerkkinoinnissaan.
-
Viitteitä
-
Common Log-formaatti
-
Tämä dokumentti
-
Dokumentin tarkoitus on määritellä, mitkä ovat tärkeimmät
ohjelmistolle asetettavat vaatimukset sekä esitellä pääpiirteet
projektista ja sen tavoitteista.
-
Luvussa 2 on esitelty yleiskuvaus ohjelmiston
suhteesta ympäristöön ja käyttäjiin sekä
tärkeimmät liittymät ja rajoitukset.
-
Luvussa 3 on kuvattu järjestelmän sisältämien
tietojen ja tietokantojen sisältö ja rakenne.
-
Luvussa 4 on kuvattu järjestelmään
tulevat toiminnot.
-
Luvussa 5 on kuvattu lukua 2 tarkemmin järjestelmän
liityntöjä.
-
Luvussa 6 on käsitelty ohjelmiston tärkeimpiä
ei-toiminnallisia ominaisuuksia.
2. Yleiskuvaus
-
Yleistä
-
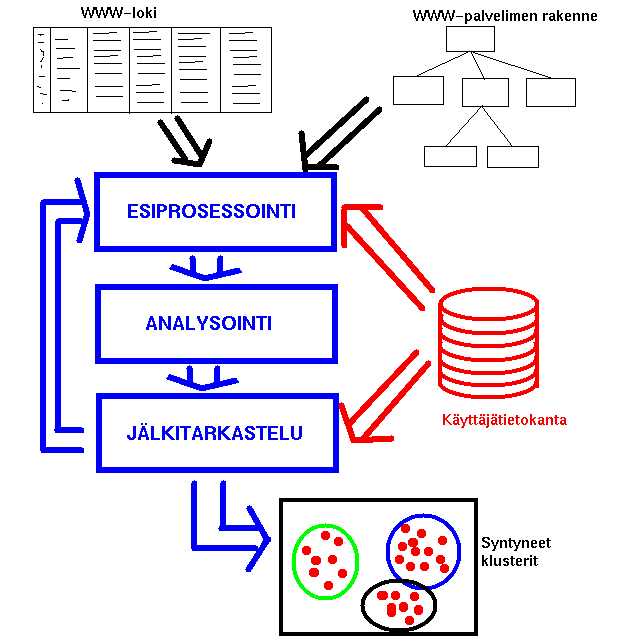
Ohjelmisto jakautuu kolmeen osaan, esiprosessointiin, varsinaiseen analyysiin
sekä syntyneiden tulosten jälkitarkasteluun. Esiprosessointivaiheessa
WWW-palvelun lokista ja ja www-palvelun rakennetiedoista rajataan klusteroitava
otanta ja konfiguroidaan varsinaisessa analyysivaiheessa käytettävää
algoritmia. Varsinaisen analyysin jälkeen seuraa jälkitarkasteluvaihe,
jossa esitetään saadut klusterit, tallennetaan tulokset ja mahdollisesti
jatketaan analysointia samoilla tai muutetuilla parametreilla. Vaiheiden
toiminnot on selvitetty myöhemmin tässä dokumentissa, seuraava
kuva selventänee ohjelman yleistä rakennetta.
-
-
Käyttöympäristö
-
Kauppalehdestä tuleva esimerkkidata käsittää paitsi
www-palvelimen lokitiedon myös käyttäjätietokannan.
Kauppalehden sivuille pääsy edellyttää käyttäjäksi
rekisteröitymistä ja samalla käyttäjä antaa joitakin
henkilötietojaan. Rekisteröityneitä käyttäjiä
on noin 45000 ja päivittäin sivuilla vierailee noin 5000 kävijää.
Näinollen jo pelkästään päivittäinen lokitieto
on useiden kymmenien megojen suuruinen.
Järjestelmän on toimittava sekä NT- että unix-ympäristössä,
sillä projektin kahdella asiakkaalla on erilaiset ympäristöt,
SmartPush-projektin käyttöympäristöksi on valittu PC-arkkitehtuuri
sekä Windows NT ja Kauppalehdellä on Unix-työasemia (Sun
UltraSPARC).
-
Liittymät
-
Järjestelmä saa siis syöttötietoja kahdesta lähteestä,
www-palvelimen tekstimuotoisesta lokitiedostosta sekä käyttäjätietokannasta,
josta saatavia tietoja voidaan käyttää esimerkiksi lokista
haettavan datan rajaamiseen tai muodostuneiden klustereiden visualisoimiseen.
Alunperin tekstimuotoisena oleva lokitieto luetaan esiprosessointivaiheessa
tietokantaan, jotta sen käsittely helpottuu. Liityntä käyttäjätietokantaan
toteutetaan tämän projektin puitteissa yhteytenä kopioon
tietokannasta, varsinainen online-yhteys elävään tietokantaan
jää mahdolliseen jatkokehitykseen.
-
-
Käyttäjät
-
Järjestelmä on tarkoitettu www-palveluntarjoajan käyttöön
eli käyttäjät ovat palvelimen ylläpitäjiä
ja sisällöntuottajia. Tulokset kiinnostavat varmasti myös
markkinointipuolta, mikäli palvelin tarjoaa maksullisia palveluita.
-
Rajoitukset
-
Toteutuskielet on jatkokehitysuunnitelmien vuoksi rajattu C++:aan sekä
Javaan. Java toteutetaan JDK 1.1:n mukaisesti ja javaosuuden edellytetään
toimivan Nescape-selaimilla.
Tietokantaliittymä on tämän projektin puitteissa rajattu
kiinteään tietokantaan eli online-yhteyttä elävään
tietokantaan ei toteuteta (mutta rajapinta tehdään niin geneeriseksi,
että tietokantaliittymämoduli on mahdolista vaihtaa mikäli
ohjelman jatkokehityksessä tulee tällaisia tarpeita).
Ohjelman käyttötapaukset on rajattu käyttäjän
komennoista tapahtuvaan käyttäjälokien prosessointiin eli
tarkoitus ei ole toteuttaa reaaliaikavaatimuksiltaan kriittistä serveriä,
joka tarkkailisi koko ajan asiakkaiden www-käyttäytymistä.
3. Tiedot ja tietokannat
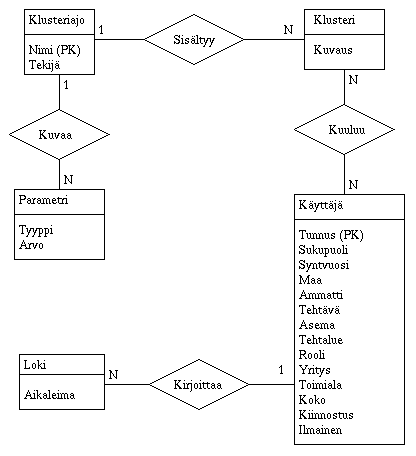
3.1. Käyttäjä- ja klusteritietokannat
Ohjelmiston tietokannoista on olemassa erillinen kuvaus
omassa dokumentissaan.
Oheinen ER-kaavio on alunperin laadittu projektin alkuvaiheessa eikä
vastaa tarkasti sitä, miten tietokannat lopulta toteutettiin, mutta
koska periaatteet ovat kuitenkin samat, antaa kaavio edelleen kuvan siitä,
mitä tietoja käyttäjä- ja klusteritietokantoihin talletetaan
sekä näiden tietojen suhteista toisiinsa.
3.2. Konfigurointitiedosto
-
Konfigurointitiedostoa käytetään määrittelemään
sellaisia klusterointiparametreja, joita harvemmin muutetaan. Näitä
ovat algoritmispesifiset parametrit sekä www-palvelun rakenne. Esimerkiksi
palelun rakenne annetaan tässä tiedostossa, jossa rrl:t voidaan
määritellä säännöllisinä lausekkeina.
Lokissa olevat url:t mapataan näillä määrityksillä
ryhmiin. Konfigurointitiedoston formaatin tarkempi määrittely
on ohjelmiston käyttöohjeessa.
3.3 Tietovirrat
Ohjelmiston tietovirroista on laadittu kaksi kaaviota, joista ensimmäinen
sisältää ohjelmiston tärkeimmät toiminnot. Suunnitteluvaiheeseen
kuuluva alphaproto sisältää korkeintaan näitä
elementtejä tai lähinnä runkoja näistä pääpainon
ollessa käyttöliittymän demoamisella.
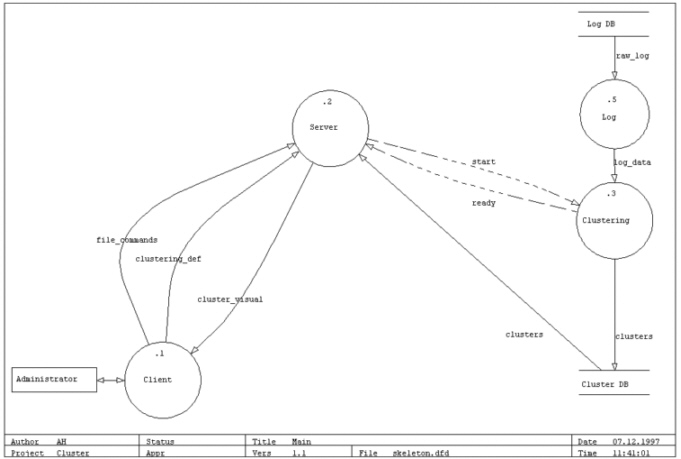
Täysikokoinen kuva
-
Client on ohjelman varsinainen käyttöliittymä, Client on
Java-applet, jonka käyttäjän www-browseri suorittaa.
-
Server kontrolloi muiden modulien toimintaa. Se keskustelee käyttäjälle
näkyvän java-sovelluksen kanssa sekä serveripäässä
toimivien klusterointi-ym. modulien kanssa. Se myös lukee ClusterDB-tietokannasta
muodostuneet klusterit voidakseen sitten lähettää ne Clientille,
joka visualisoi klusterit käyttäjälle.
-
Clustering on varsinaisen raa'an työn tekijä, komponentti, joka
saa palvelimelta klusterointikäskyn, Log:lta lokidatan ja muodostaa
näistä klustereita valitulla klusterointialgoritmilla. Valmiit
klusterit se tallettaa ClusterDB-tietokantaan ja ilmoittaa serverille työn
valmistuneen.
-
Log lukee lokitietokannasta käyttäjän valitseman osan, muokkaa
tietoa käyttäjän haluamalla tavalla, ja tekee tiedosta klusterointikelpoista.
Laajennettu tietovirtakaavio käsittää jo kaikki lopulliseen
ohjelmistoon tulevat tietovirrat:
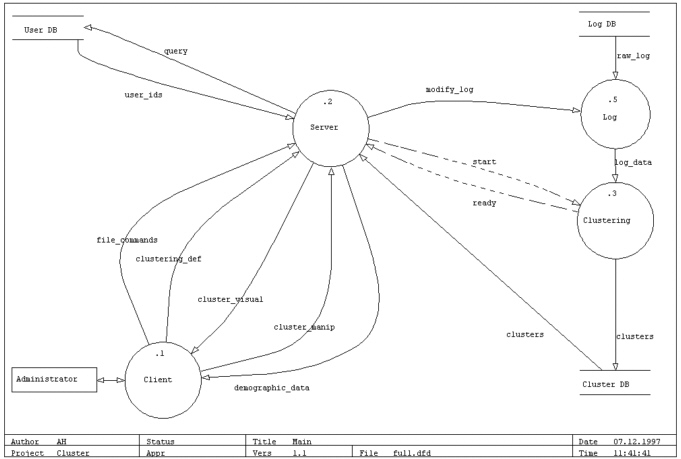
Täyskokoinen kuva
Olennaisimmat erot edellä esiteltyyn yksinkertaistettuun versioon
ovat lähinnä tietokantaliitynnöissä:
-
Käyttäjien demografisia tietoja sisältävä tietokanta
on lisätty. Näitä tietoja käytetään kahteen
tarkoitukseen:
-
Lokitietojen muokkaus (tietovirta modify_log). Klusteroitavaksi voidaan
valita tietty osajoukko käyttäjiä.
-
Klustereita voidaan tarkastella tutkimalla niiden jäsenten demografisia
tietoja.
-
Login toimintoihin on lisätty yllämainittu modifioitavuus.
Lisäksi on Clientin ja Serverin välistä liikennettä
lisätty kattamaan uusien toimintojen vaatima tiedonvälitys.
4. Toiminnot
Tässä luvussa määritellään tarkasti ohjelmiston
vaatimukset, käytettävä formaatti on määritelty
alla olevalla tavalla. Joissain kohdissa on käytetty lyhennettä
TBD, joka tarkoittaa To Be Defined. Tämä tarkoittaa,että
kyseinen kohta määritellään projektin myöhäisemmässä
vaiheessa.
Vaatimusmäärittelyn formaatti:
-
Vapaata tekstiä, vaatimuksessa olevien sanojen määritelmiä
ja kuvauksia
-
Vaatimus luku.luokka.juokseva_numero
-
[ tarkka vaatimus ]
4.1 Klusterointiin liittyvät toiminnot
-
Ohjelmiston perustavin vaatimus on toimiva klusterointi,joka perustuu online-käyttäjien
käyttäytymiseen kyseisellä www-palvelimella. Tieto käyttäytymisestä
löytyy lokitietokannasta. Saatujen klustereiden määrä
ei ole vakio, vaan se riippuu klusteroinnille annetuista syötteistä,
etenkin lokikannasta
-
Vaatimus 4.1.0 :
-
Klusteroinnin tarkoitus on muodostaa erilaisia ryhmiä, joihin online-palvelun
käyttäjät jakautuvat.
-
Lokikanta muodostuu kolmesta kentästä,User_Id:sta, URL-polusta
ja aikaleimasta. Nämä tiedot muodostavat pohjan klusteroinnille.
Klusterointia suoritetaan joko URL-polusta,aikaleimasta tai sitten molemmista
riippuen siitä miten käyttäjä tilanteen haluaa.
-
Vaatimus 4.1.1 :
-
Klusteroinnin pohjaksi on mahdollisuus valita joko URL-polku,aikaleima
tai molemmat.
-
URL-polun identifiointi tapahtuu init-tiedoston mukaan, josta löytyy
tieto palvelimen rakenteesta, jonka perusteella käyttäjän
lukemat sivut voidaan jaotella osastoihin. Näin ollen siirrytään
raa'asta lokikannasta tarkasti määriteltyyn virtuaalilokikantaan.
-
Vaatimus 4.1.2 :
-
Ohjelma lukee init-tiedoston, joka määrittelee osastojaon URL-poluille.
Raa'an lokin URL-kenttä korvataan osastolla, johon URL kuuluu.
-
Virtuaalilokista voidaan poistaa käyttäjiä,joiden käyttäytymisestä
admin ei ole kiinnostunut. Tässä reduktiossa käytetään
hyväksi User_DB:tä, joka palauttaa joukon käyttäjiä
(user_ids) jotka vastasivat ohjelmiston käyttäjän haluamaa
kyselyä kannasta.
-
Vaatimus 4.1.3 :
-
Virtuaalilokista on mahdollista poistaa ohjelmiston käyttäjän
valitsemilla perusteilla joukko palvelunkäyttäjiä.
-
Klusterointi käyttää hyväksi virtuaalilokia. Seuraavaksi
määritellään mahdolliset klusterointifunktiot, joiden
perusteella klusterointitulos saavutetaan. Perusyksikkönä on
sessio (session määrittelyperusteena on aika kahden haun välillä
TBD). Sessio muodostuu aikaleimoista, joissa on tieto siitä, mihin
kellonaikaan palvelun käyttäja on lukenut sivuja. Tämä
informaatio muodostaa toisen perusluokan, jonka perusteella klusterointia
voidaan suorittaa. Ensimäinen perusluokka on URL-polun (osaston) suhteen
klusterointi. Mielenkiintoista on myös paljon palvelua käyttävien
asiakkaiden käyttäytyminen.
-
Vaatimus 4.1.4 :
-
Mega-userien perusteella klusterointi. Riippuvainen lokientryjen määrästä
TBD.
-
Vaatimus 4.1.5 :
-
Klusterointi polkujen mukaan, ohjelmiston käyttäjä voi valita
virtuaalilokista osastoja joiden mukaan klusterointi tapahtuu.
-
Vaatimus 4.1.6 :
-
Klusterointi session perusteella (aikaleimoista) tunnin tarkkuudella.
-
Vaatimus 4.1.7 :
-
Klusterointi session perusteella (aikaleimoista) päivän tarkkuudella.
-
Vaatimus 4.1.8 :
-
Klusterointi session perusteella (aikaleimoista) arkipäivän/viikonlopun
tarkkuudella.
4.2 Klustereiden tallennukseen liittyvät toiminnot
-
Klustereiden tallennus on tarkeä osa järjestelmää,
näin voidaan seurata pidemmällä aikavälillä eri
klustereiden muuttumista. Ohjelmisto huolehtii myös klustereiden merkinnästä,etteivät
klusterit mene sekaisin kannassa.
-
Vaatimus 4.2.0 :
-
Saadut klusterit voidaan tallentaa erilliseen SQL-klustertietokantaan.
-
Vaatimus 4.2.1 :
-
Ohjelmiston käyttäjällä on mahdollisuus lukea klustereita
klustertietokannasta.
4.3 Klustereiden visualisointiin liittyvät toiminnot
-
Kolmantena päätoimintona on saatujen klustereiden visualisointi.
Visualisointiin ei kehitetä tämän projektin puitteissa monimutkaisia
työkaluja, ainoastaan yksinkertaiset pie chart-tyyppiset kuvaukset.
Sen sijaan saadut klusteritiedot tallennetaan SQL-kantaan, josta ohjelmiston
käyttäjä voi hakea tiedot ja käyttää niiden
visualisointiin haluamiaan työkaluja. Tällaiseen ratkaisuun päädyttiin,
koska valmiiden tietokantojen visualisointiin on olemassa lukuisia kehittyneitä
työkaluja eikä pyörän uudelleenkeksimistä pidetty
tarpeellisena.
-
Vaatimus 4.3.0 :
-
Klusterit visualisoidaan käyttämällä pie-chart teknikkaa.
-
Vaatimus 4.3.1 :
-
Klusterin visualinen koko on suoraan verrannollinen klusterissa olevien
henkilöiden lukumäärään.
5. Ulkoiset liittymät
5.1. Käyttöliittymä
Käyttöliittymä koostuu seuraavasti kolmesta loogisesta
kokonaisuudesta: Klusteroinnin määrittely, aloittaminen ja seuraaminen
-
Klusteroinnin määrittely, aloittaminen ja seuraaminen
-
Tässä dialogissa käyttäjä voi valita lokin suodatukseen
vaikuttavat parametrit, jotka voidaan jakaa kahteen loogisesti erilliseen
ryhmään. Ensimmäisenä käyttäjä voi valita
suodatusparametreja käyttäjätietojen perusteella. Näitä
tietoja ovat ikä, sukupuoli, yritys-/yksityiskäyttäjä,
ilmais-/maksullisten palvelujen käyttäjä, maa, miten kauan
on käyttänyt palvelua jne. Toisena käyttäjä voi
valita suodatusparametreiksi erilaisia aikajaksoja, jotka ovat: lokin keruuaika,
päivän sisällä oleva käyttöaika (esim. 8-16)
sekä viikon sisällä oleva käyttöaika(esim. ma-pe).
Klusterointitulokselle annetaan myöskin nimi.
-
Kun käyttäjä on valinnut sopivat suodatusparametrit, hän
voi aloittaa klusteroinnin. Klusteroinnin edistymisestä ilmoitetaan
käyttäjälle(esim. progress bar).
-
Klusterointitulosten visualisointi
-
Tämä osa tulee pääikkunaan. klusterointitulosta voidaan
tarkastella kahdella tasolla. Ylemmällä tasolla näkyvät
kaikki klusterit ja niiden suhde toisiinsa(esim. tietyn kokoiset ympyrät
tietyllä etäisyydellä toisistaan). Kun klusteria klikkaa,
tulee näkyviin tarkempi tieto klusterista. Klusterin sisäistä
rakennetta voi tarkastella suhteessa sen sisältämien käyttäjien
demografisiin tietoihin. Näitä tietoja ovat esimerkiksi sukupuoli,
maa, ammatti, asema, tehtävä, toimiala, käyttöikä,
yritys/yksityiskäyttäjä. Tarkastelumuotona käytetään
esimerkiksi pie chartia
-
Klusterointitulosten hallinta
-
Tässä dialogissa vanhoja klusterikannassa olevia klusterointituloksia
voidaan ladata, selata ja tuhota.
6. Muut ominaisuudet
-
Suorituskyky
-
Koska ohjelmisto on tarkoitettu ajettavaksi eräajotyyppisesti eikä
pyörimään taustalla, ei varsinaisen analyysivaiheen tehokkuus
ole kriittisimpiä tekijöitä ohjelman käytettävyyden
kannalta. Syöttötiedot ovat joka tapauksessa niin isoja, että
analyysivaiheen kesto mitataan kuitenkin vähintään kymmenissä
minuuteissa, todennäköisesti tunneissa. Sen sijaan ohjelman interaktiivinen
osa eli analyysin parametrien muuttaminen sekä tulosten jälkitarkastelu
ja visualisointi on luonnollisesti tapahduttava jouhevasti.
-
Tämänhetkisen käsityksemme mukaan Jva-toteutuskin on riittävän
tehokas ohjelmistolle asetettuihin vaatimuksiin nähden, mutta asia
on tarkastettava algoritmitoteutuksen ensimmäisen version valmistuttua
ja mikäli klusterointi vaatii kohtuuttomasti aikaa, on varsinainen
klusterointipalikka toteutettava esim. C:llä tai C++:lla tehokkuuden
parantamiseksi.
-
Käytettävyys
-
Koska ohjelma tulee ensisijaisesti www-palvelimen ylläpidon käyttöön,
voidaan olettaa loppukäyttäjien olevan tottuneita tietokoneen
käyttäjiä, jotka ovat kiinnostuneita asiasta ja tarvittaessa
valmiit jopa lukemaan manuaaleja. Niinpä onkin tärkeämpää
keskittyä toimintojen itsestäänselvyyden sijasta tulosten
hyvään visualisointiin sekä siihen, että ohjelmisto
olisi tottuneelle käyttäjälle looginen, sujuva ja tehokas
käyttää.
-
Ylläpidettävyys
-
Ohjelman ylläpidettävyys ja modulaarisuus ovat tärkeitä,
sillä molemmilla asiakkailla on kiinnostusta jatkaa ohjelmiston jatkokehitystä
mikäli projektin tulokset ovat positiivisia. Mahdollisimman suuri
osa ohjelmistosta tulisi toteuttaa erillisinä moduleina, jotka voidaan
korvata toisilla, esimerkiksi varsinaisen klusterointialgoritmin muuttaminen
jälkeenpäin voi olla tarpeellista mikäli klusterointitarpeet
eroavat kovin paljon tässä vaiheessa ajatelluista.
-
Siirrettävyys
-
Ohjelmiston siirrettävyys on huomioitava koko projektin aikana jo
pelkästään siitä syystä, että ohjelmisto
on heti aluksi menossa sekä NT- että unix-ympäristöön.
pemakela@cc.hut.fi
stlaitin@cc.hut.fi
jarautia@cc.hut.fi
{kind=link}