Tik-76.115 Toiminnallinen mððrittely
Cluster
http://www.hut.fi/~pemakela/ot/documents/to.html
Viimeksi pðivitetty 3.11. 1997.
Sisðllysluettelo
Yhteenveto
1. Johdanto
2. Yleiskuvaus
3. Tiedot ja tietokanta
4. Toiminnot
5. Ulkoiset liittymðt
6. Muut ominaisuudet
- Projekti
- Kyseessð olevan projektin tarkoituksena on laatia ohjelmisto, joka lukee
www-palvelimen lokitietoja sekð tiedot www-palvelun rakenteesta
ja muodostaa nðistð tiedoista kðyttðjðklustereita, ts. jakaa
www-palvelimella kðyneet kðyttðjðt erilaisiin ryhmiin perustuen
siihen, mitð, milloin, missð jðrjestyksessð jne. kðyttðjðt ovat
palvelimelta hakeneet. Palvelimen kðyttðjðtietojen rajauksessa
sekð saatujen klusterien jðlkitarkastelussa voidaan kðyttðð hyvðksi
niitð henkil—tietoja, jotka kðyttðjðt ovat itsestððn antaneet
rekister—ityessððn palvelun kðyttðjiksi. Ohjelmiston kehityksessð kðytetððn
esimerkkipalvelimena Kauppalehti
Online-palvelua, sen www-palvelimen lokitietoja sekð kðyttðjðtietokantaa.
- Tðmð dokumentti
- Tðmð dokumentti, toiminnallinen mððrittely, on tarkennettu
versio vaatimusmððrittelystð ja tðmðn dokumentin
tarkoituksena on tarkentaa asiakkaan vaatimukset ja toiveet sekð rajata
ja mððritellð mahdollisista ominaisuuksista ne mitð toteutetaan sekð
miten ne toteutetaan. Dokumentissa esitellððn ohjelma pððpiirteittðin,
sen liittymðt, kðytt—ympðrist—, kðyttðjðt jne., kuvataan ohjelmiston
sisðltðmien tietokantojen sisðll—t, ylimmðn tason tietovirtakaaviot
sekð mððritellððn ohjelmistoon kuuluvat toiminnot.
- Ohjelmiston yleiskuvaus
- Ohjelmisto jakautuu ylimmðllð tasolla kolmeen loogiseen mosuliin:
tiedon esiprosessointiin, analyysiin sakð jðlkitarkasteluun.
Esiprosessointi kðsittðð klusteroitavan aineiston rajauksen sekð
varsinaisen klusteroinnin konfiguroimisen ennen varsinaista analyysivaihetta,
jossa saaduista tiedoista muodostetaan klustereita. Jðlkitarkasteluvaiheessa
saadut klusteritiedot tallennetaan jatkotarkastelua ja -kðytt—ð varten,
tuloksia voidaan visualisoida ja niiden perusteella voidaan ruveta
suorittamaan uutta analyysia joko tyhjðstð tai sitten edellisen
analyysin tuloksista tarkentamalla.
- Ohjelmisto tehdððn C++:lla sekð Javalla ja sen on toimittava sekð
Windows NT-ettð Unix-ympðrist—issð. Ohjelmiston kðytt—liittymð on
java-pohjainen ja sitð voidaan kðyttðð Netscape-selaimen 3- ja
4-versioilla. Ohjelmiston ensisijaisia kðyttðjið ovat www-palvelimien
yllðpitðjðt ja palveluntarjoajat.
- Liittymðt
- Ohjelmisto lukee www-palvelimen rakenteen erillisestð tiedostosta
ja lokitiedot www-palvelimen tuottamasta tekstimuotoisesta lokista.
Tðmð loki muunnetaan my—s tietokannaksi kðsittelyn helppottamiseksi.
Kðyttðjðtiedot ovat jo valmiiksi Oracle-kannassa.
- Toiminnot
- Toiminnot on jaettu kolmeen ryhmððn: varsinaiseen klusterointiin
liittyvðt toiminnot, tallennukseen liittyvðt toiminnot sekð
visualisointiin liittyvðt toiminnot. Toiminnot on selvitetty
tarkemmin luvussa 4.
- Kðytt—liittymð
- Kðytt—liittymð on jaettu kðyttðjðn kannalta katsottuna
kolmeen loogisen kokonaisuuteen: klusterointi ja siihen liittyvðt
konfigurointi- ym. toimenpiteet, tulosten visualisointi sekð
tulosten hallinta, joka kðsittðð mahdollisuuden tallentaa,
ladata ja vertailla eri aikoina tehtyjð klusterointianalyyseja.
- Tavoitteet
- Projektin tarkoituksena on laatia ohjelmisto, joka saamiensa www-palvelimen
lokitietojen pohjalta klusteroi kðyttðjið eli jaottelee kðyttðjðt erilaisiin
ryhmiin sen mukaan mitð he ovat www-palvelimelta hakeneet. Nðin saatuja
tietoja kðyttðjien klusteroitumisesta on tarkoitus kðyttðð mm. palvelimen
sisðll—n kehittðmiseen, markkinointiin jne. Projektilla on kaksikin
asiakasta; TKK/TAI:n SmartPush-projekti sekð Aamulehtiyhtymð, varsinaisesti
tðssð vaiheessa Kauppalehti Online, joka
tarjoaa projektin kðytt——n www-palvelimensa lokitiedot. SmartPushin, jonka
osaksi tðtð projektia kaavaillaan, lopullinen tavoite on kyetð tarjoamaan
kðyttðjille vinkkejð uusista heitð kiinnostavista aiheista sen perusteella,
millaista tietoa he ovat tðhðn mennessð hakeneet ja mitð muut samoista
asioista kiinnostuneet ovat lukeneet. Kauppalehden tavoitteena on paitsi
seurannan kautta kehittðð palvelimensa laatua ja kiinnostavuutta my—s
kðyttðð saatuja tietoja mediamerkkinoinnissaan.
- Viitteitð
-
Common Log-formaatti
- Tðmð dokumentti
-
Dokumentin tarkoitus on mððritellð, mitkð ovat tðrkeimmðt ohjelmistolle
asetettavat vaatimukset sekð esitellð pððpiirteet projektista
ja sen tavoitteista.
- Luvussa 2 on esitelty yleiskuvaus
ohjelmiston suhteesta ympðrist——n ja kðyttðjiin sekð tðrkeimmðt
liittymðt ja rajoitukset.
- Luvussa 3 on kuvattu jðrjestelmðn
sisðltðmien tietojen ja tietokantojen sisðlt— ja rakenne.
- Luvussa 4 on kuvattu jðrjestelmððn
tulevat toiminnot.
- Luvussa 5 on kuvattu lukua 2 tarkemmin
jðrjestelmðn liitynt—jð.
- Luvussa 6 on kðsitelty ohjelmiston tðrkeimpið
ei-toiminnallisia ominaisuuksia.
- Yleistð
- Ohjelmisto jakautuu kolmeen osaan, esiprosessointiin, varsinaiseen
analyysiin sekð syntyneiden tulosten jðlkitarkasteluun.
Esiprosessointivaiheessa WWW-palvelun lokista ja ja www-palvelun
rakennetiedoista rajataan klusteroitava otanta ja konfiguroidaan
varsinaisessa analyysivaiheessa kðytettðvðð algoritmia. Varsinaisen
analyysin jðlkeen seuraa jðlkitarkasteluvaihe, jossa esitetððn saadut
klusterit, tallennetaan tulokset ja mahdollisesti jatketaan analysointia
samoilla tai muutetuilla parametreilla. Vaiheiden toiminnot on selvitetty
my—hemmin tðssð dokumentissa, seuraava kuva selventðnee ohjelman
yleistð rakennetta.
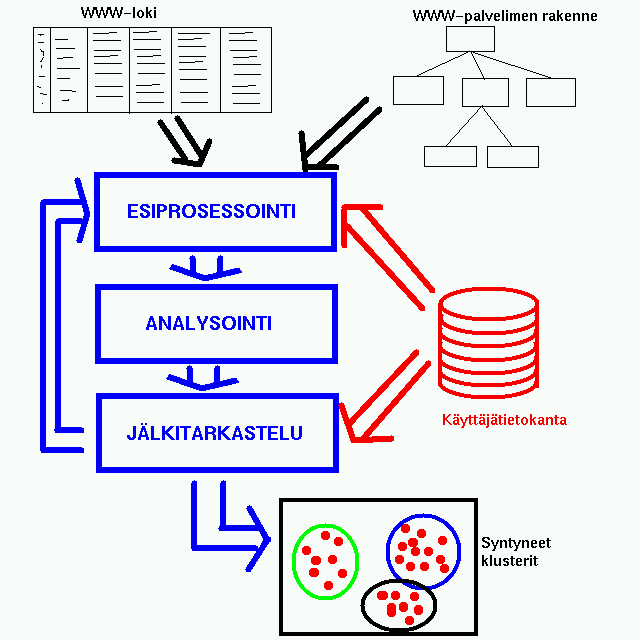
- Kðytt—ympðrist—
- Kauppalehdestð tuleva esimerkkidata kðsittðð paitsi www-palvelimen
lokitiedon my—s kðyttðjðtietokannan. Kauppalehden sivuille pððsy
edellyttðð kðyttðjðksi rekister—itymistð ja samalla kðyttðjð
antaa joitakin henkil—tietojaan. Rekister—ityneitð kðyttðjið on noin 45000 ja
pðivittðin sivuilla vierailee noin 5000 kðvijðð. Nðinollen jo pelkðstððn
pðivittðinen lokitieto on useiden kymmenien megojen suuruinen.
Jðrjestelmðn on toimittava sekð NT- ettð unix-ympðrist—ssð, sillð
projektin kahdella asiakkaalla on erilaiset ympðrist—t,
SmartPush-projektin kðytt—ympðrist—ksi on valittu Windows NT ja
Kauppalehdellð on Sun UltraSPARC-koneita.
- Liittymðt
- Jðrjestelmð saa siis sy—tt—tietoja kahdesta lðhteestð, www-palvelimen
tekstimuotoisesta lokitiedostosta sekð kðyttðjðtietokannasta, josta
saatavia tietoja voidaan kðyttðð esimerkiksi lokista haettavan datan
rajaamiseen tai muodostuneiden klustereiden visualisoimiseen. Alunperin
tekstimuotoisena oleva lokitieto luetaan esiprosessointivaiheessa
tietokantaan, jotta sen kðsittely helpottuu. Liityntð
kðyttðjðtietokantaan toteutetaan tðmðn projektin puitteissa yhteytenð
kopioon tietokannasta, varsinainen online-yhteys elðvððn tietokantaan
jðð mahdolliseen jatkokehitykseen.
-
- Kðyttðjðt
- Jðrjestelmð on tarkoitettu www-palveluntarjoajan kðytt——n eli
kðyttðjðt ovat palvelimen yllðpitðjið ja sisðll—ntuottajia.
Tulokset kiinnostavat varmasti my—s markkinointipuolta, mikðli palvelin
tarjoaa maksullisia palveluita.
- Rajoitukset
- Toteutuskielet on jatkokehitysuunnitelmien vuoksi rajattu C++:aan
sekð Javaan. Java toteutetaan JDK 1.1:n mukaisesti ja javaosuuden
edellytetððn toimivan Nescape-selaimilla.
Tietokantaliittymð on tðmðn projektin puitteissa rajattu kiinteððn
tietokantaan eli online-yhteyttð elðvððn tietokantaan ei toteuteta (mutta
rajapinta tehdððn niin geneeriseksi, ettð tietokantaliittymðmoduli on
mahdolista vaihtaa mikðli ohjelman jatkokehityksessð tulee tðllaisia
tarpeita).
Ohjelman kðytt—tapaukset on rajattu kðyttðjðn komennoista tapahtuvaan
kðyttðjðlokien prosessointiin eli tarkoitus ei ole toteuttaa
reaaliaikavaatimuksiltaan kriittistð serverið, joka tarkkailisi koko
ajan asiakkaiden www-kðyttðytymistð.
3.1. Kðyttðjðtietokanta
Kðyttðjð- ja klusteritietokannoissa kðytetyt taulut selviðvðt oheisesta
ER-kaaviosta:
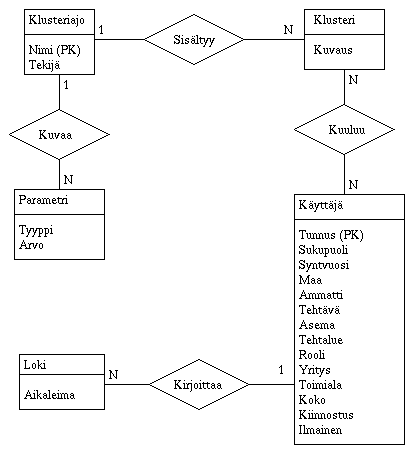
3.2. Init-tiedosto
- Init-tiedostoa kðytetððn mððrittelemððn sellaisia
klusterointiparametreja,
joita harvemmin muutetaan. Nðitð ovat algoritmispesifiset parametrit sekð
www-palvelun rakenne. Webbipalvelun rakenne ilmoitetaan tiedostossa
seuraavasti:
- [looginen ryhmð]:
- [url1]
- [url2]
- Url:t voidaan mððritellð sððnn—llisinð lausekkeina. Lokissa olevat url:t
mapataan nðillð mððrityksillð ryhmiin.
3.3 Tietovirrat
Ohjelmiston tietovirroista on laadittu kaksi kaaviota, joista ensimmðinen
sisðltðð ohjelmiston tðrkeimmðt toiminnot. Nðmð toiminnot on tarkoitus saada
alphaprotovaiheessa demottavaan kuntoon.
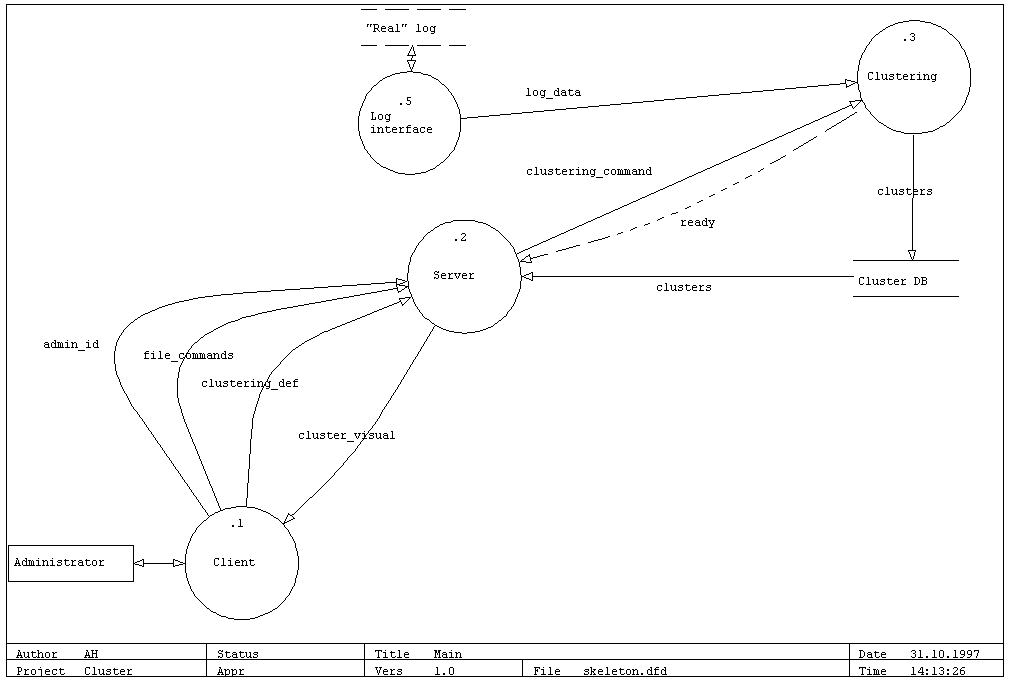
Laajennettu tietovirtakaavio kðsittðð jo kaikki lopulliseen ohjelmistoon
tulevat tietovirrat.

Tðssð luvussa mððritellððn tarkasti ohjelmiston vaatimukset,
kðytettðvð formaatti on mððritelty alla olevalla tavalla.
Joissain kohdissa on kðytetty lyhennettð TBD, joka
tarkoittaa To Be Defined. Tðmð tarkoittaa,ettð kyseinen kohta
mððritellððn projektin my—hðisemmðssð vaiheessa.
Vaatimusmððrittelyn formaatti:
- Vapaata tekstið, vaatimuksessa olevien sanojen mððritelmið ja
kuvauksia
- Vaatimus luku.luokka.juokseva_numero
- [ tarkka vaatimus ]
4.1 Klusterointiin liittyvðt toiminnot
- Ohjelmiston perustavin vaatimus on toimiva klusterointi,joka perustuu
online-kðyttðjien kðyttðytymiseen kyseisellð www-palvelimella. Tieto
kðyttðytymisestð l—ytyy lokitietokannasta.
Saatujen klustereiden mððrð ei ole vakio, vaan se riippuu
klusteroinnille annetuista sy—tteistð, etenkin lokikannasta
- Vaatimus 4.1.0 :
- Klusteroinnin tarkoitus on muodostaa erilaisia ryhmið,
joihin online-palvelun kðyttðjðt jakautuvat.
- Lokikanta muodostuu kolmesta kentðstð,User_Id:sta,
URL-polusta ja aikaleimasta. Nðmð tiedot muodostavat pohjan
klusteroinnille. Klusterointia suoritetaan joko URL-polusta,aikaleimasta
tai sitten molemmista riippuen siitð miten kðyttðjð tilanteen haluaa.
- Vaatimus 4.1.1 :
- Klusteroinnin pohjaksi on mahdollisuus valita joko
URL-polku,aikaleima tai molemmat.
- URL-polun identifiointi tapahtuu init-tiedoston mukaan,
josta l—ytyy tieto palvelimen rakenteesta,
jonka perusteella kðyttðjðn lukemat sivut voidaan jaotella osastoihin.
Nðin ollen siirrytððn raa'asta lokikannasta tarkasti mððriteltyyn
virtuaalilokikantaan.
- Vaatimus 4.1.2 :
- Ohjelma lukee init-tiedoston, joka mððrittelee
osastojaon URL-poluille. Raa'an lokin URL-kenttð korvataan osastolla,
johon URL kuuluu.
- Virtuualilokista voidaan poistaa kðyttðjið,joiden kðttðytymisestð
admin ei ole kiinnostunut. Tðssð reduktiossa kðytetððn
hyvðksi User_DB:tð, joka palauttaa joukon kðyttðjið (user_ids)
jotka vastasivat ohjelmiston kðyttðjðn haluamaa kyselyð kannasta.
- Vaatimus 4.1.3 :
- Virtuaalilokista on mahdollista poistaa ohjelmiston
kðyttðjðn valitsemilla perusteilla joukko palvelunkðyttðjið.
- Klusterointi kðyttðð hyvðksi virtuaalilokia. Seuraavaksi mððritellððn
mahdolliset klusterointifunktiot, joiden perusteella klusterointitulos
saavutetaan. Perusyksikk—nð on sessio (session mððrittelyperusteena on
aika kahden haun vðlillð TBD). Sessio muodostuu aikaleimoista, joissa
on tieto siitð, mihin
kellonaikaan palvelun kðyttðja on lukenut sivuja. Tðmð informaatio
muodostaa toisen perusluokan, jonka perusteella klusterointia voidaan
suorittaa.
Ensimðinen perusluokka on URL-polun (osaston) suhteen klusterointi.
Mielenkiintoista on my—s paljon palvelua kðyttðvien asiakkaiden
kðyttðytyminen.
- Vaatimus 4.1.4 :
- Mega-userien perusteella klusterointi. Riippuvainen
lokientryjen mððrðstð TBD.
- Vaatimus 4.1.5 :
- Klusterointi polkujen mukaan, ohjelmiston kðyttðjð voi valita
virtuaalilokista osastoja joiden mukaan klusterointi tapahtuu.
- Vaatimus 4.1.6 :
- Klusterointi session perusteella (aikaleimoista) tunnin tarkkuudella.
- Vaatimus 4.1.7 :
- Klusterointi session perusteella (aikaleimoista) pðivðn tarkkuudella.
- Vaatimus 4.1.8 :
- Klusterointi session perusteella (aikaleimoista) arkipðivðn/viikonlopun tarkkuudella.
4.2 Klustereiden tallennukseen liittyvðt toiminnot
- Klustereiden tallennus on tarkeð osa jðrjestelmðð, nðin voidaan
seurata pidemmðllð aikavðlillð eri klustereiden muuttumista.
Ohjelmisto huolehtii my—s klustereiden merkinnðstð,etteivðt klusterit
mene sekaisin kannassa.
- Vaatimus 4.2.0 :
- Saadut klusterit voidaan tallentaa erilliseen
SQL-klustertietokantaan.
- Vaatimus 4.2.1 :
- Ohjelmiston kðyttðjðllð on mahdollisuus lukea klustereita
klustertietokannasta.
4.3 Klustereiden visualisointiin liittyvðt toiminnot
- Kolmantena pððtoimintona on saatujen klustereiden visualisointi.
Visualisointiin ei kehitetð tðmðn projektin puitteissa monimutkaisia
ty—kaluja, ainoastaan yksinkertaiset pie chart-tyyppiset kuvaukset.
Sen sijaan saadut klusteritiedot tallennetaan SQL-kantaan, josta
ohjelmiston kðyttðjð voi hakea tiedot ja kðyttðð niiden visualisointiin
haluamiaan ty—kaluja. Tðllaiseen ratkaisuun pððdyttiin, koska valmiiden
tietokantojen visualisointiin on olemassa lukuisia kehittyneitð ty—kaluja
eikð py—rðn uudelleenkeksimistð pidetty tarpeellisena.
- Vaatimus 4.3.0 :
- Klusterit visualisoidaan kðyttðmðllð pie-chart teknikkaa.
- Vaatimus 4.3.1 :
- Klusterin visualinen koko on suoraan verrannollinen klusterissa
olevien henkil—iden lukumððrððn.
5.1. Kðytt—liittymð
Kðytt—liittymð koostuu seuraavasti kolmesta loogisesta
kokonaisuudesta: Klusteroinnin mððrittely, aloittaminen ja seuraaminen
- Klusteroinnin mððrittely, aloittaminen ja seuraaminen
- Tðssð dialogissa kðyttðjð voi valita lokin suodatukseen
vaikuttavat parametrit, jotka voidaan jakaa kahteen loogisesti erilliseen
ryhmððn. Ensimmðisenð kðyttðjð voi valita suodatusparametreja
kðyttðjðtietojen perusteella. Nðitð tietoja ovat ikð, sukupuoli,
yritys-/yksityiskðyttðjð, ilmais-/maksullisten palvelujen kðyttðjð, maa,
miten kauan on kðyttðnyt palvelua jne. Toisena kðyttðjð voi valita
suodatusparametreiksi erilaisia
aikajaksoja, jotka ovat: lokin keruuaika, pðivðn sisðllð oleva kðytt—aika
(esim. 8-16) sekð viikon sisðllð oleva kðytt—aika(esim. ma-pe).
Klusterointitulokselle annetaan my—skin nimi.
- Kun kðyttðjð on valinnut sopivat suodatusparametrit, hðn
voi aloittaa klusteroinnin. Klusteroinnin edistymisestð ilmoitetaan
kðyttðjðlle(esim. progress bar).
- Klusterointitulosten visualisointi
- Tðmð osa tulee pððikkunaan. klusterointitulosta voidaan tarkastella
kahdella tasolla. Ylemmðllð tasolla nðkyvðt kaikki klusterit ja niiden
suhde toisiinsa(esim. tietyn kokoiset ympyrðt tietyllð etðisyydellð
toisistaan). Kun klusteria klikkaa, tulee nðkyviin tarkempi tieto
klusterista. Klusterin sisðistð rakennetta voi tarkastella suhteessa sen
sisðltðmien kðyttðjien demografisiin tietoihin. Nðitð tietoja ovat
esimerkiksi sukupuoli, maa, ammatti, asema, tehtðvð, toimiala, kðytt—ikð,
yritys/yksityiskðyttðjð. Tarkastelumuotona kðytetððn esimerkiksi
pie chartia
- Klusterointitulosten hallinta
- Tðssð dialogissa vanhoja klusterikannassa olevia klusterointituloksia
voidaan ladata, selata ja tuhota.
6. Muut ominaisuudet
- Suorituskyky
- Koska ohjelmisto on tarkoitettu ajettavaksi erðajotyyppisesti
eikð py—rimððn taustalla, ei varsinaisen analyysivaiheen tehokkuus
ole kriittisimpið tekij—itð ohjelman kðytettðvyyden kannalta. Sy—tt—tiedot
ovat joka tapauksessa niin isoja, ettð analyysivaiheen kesto mitataan
kuitenkin vðhintððn kymmenissð minuuteissa, todennðk—isesti tunneissa.
Sen sijaan ohjelman interaktiivinen osa eli analyysin parametrien muuttaminen
sekð tulosten jðlkitarkastelu ja visualisointi on luonnollisesti tapahduttava
jouhevasti.
- Kðytettðvyys
- Koska ohjelma tulee ensisijaisesti www-palvelimen yllðpidon kðytt——n,
voidaan olettaa loppukðyttðjien olevan tottuneita tietokoneen kðyttðjið,
jotka ovat kiinnostuneita asiasta ja tarvittaessa valmiit jopa lukemaan
manuaaleja. Niinpð onkin tðrkeðmpðð keskittyð toimintojen itsestððnselvyyden
sijasta tulosten hyvððn visualisointiin sekð siihen, ettð ohjelmisto olisi
tottuneelle kðyttðjðlle looginen, sujuva ja tehokas kðyttðð.
- Yllðpidettðvyys
- Ohjelman yllðpidettðvyys ja modulaarisuus ovat tðrkeitð, sillð
molemmilla asiakkailla on kiinnostusta jatkaa ohjelmiston jatkokehitystð
mikðli projektin tulokset ovat positiivisia. Mahdollisimman suuri osa
ohjelmistosta tulisi toteuttaa erillisinð moduleina, jotka voidaan korvata
toisilla, esimerkiksi varsinaisen klusterointialgoritmin muuttaminen
jðlkeenpðin voi olla tarpeellista mikðli klusterointitarpeet eroavat
kovin paljon tðssð vaiheessa ajatelluista.
- Siirrettðvyys
- Ohjelmiston siirrettðvyys on huomioitava koko projektin aikana jo
pelkðstððn siitð syystð, ettð ohjelmisto on heti aluksi menossa sekð
NT- ettð unix-ympðrist——n.
pemakela@cc.hut.fi
stlaitin@cc.hut.fi
jarautia@cc.hut.fi