The SCHEMESTATION cross-compiler and assembler are used to produce binary byte code objects to be run in the SCHEMESTATION operating system simulator.
This document specifies the implementation aspects of the compiler and the assembler.
The compiler is implemented in Scheme and the assembler in C. The assembler is written in C because the library implementing SCHEMESTATION heap handling is written in C. Were the assembler written in Scheme, heap creation should be re-implemented in Scheme because byte code objects produced by the assembler are essentially linearized heaps. On the other hand, it is preferable to keep the amount of non-Scheme code in minimum in order to make later porting of the compiler to the SCHEMESTATION platform as easy as possible.
This document specifies the compiler first and the assembler afterwards.
The overall structure of the compiler is presented in Fig 1.
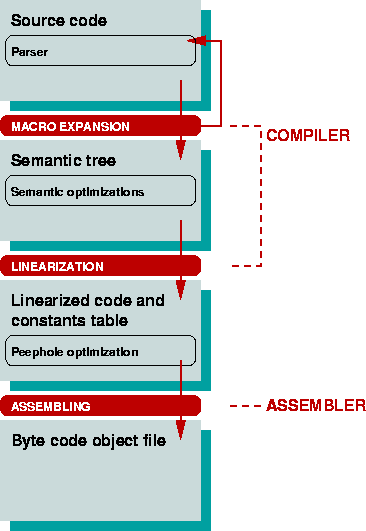
The lexical structure of legal source code accepted by the compiler is a sequence of tokens, where the structure of a token is defined by the following grammar (borrowed modified from [1]).
{token} --> {identifier}
| {boolean}
| {number}
| {character}
| {string}
| {bit-string}
| ( | ) | #( | ' | ` | , | ,@ | .
{delimiter} --> {whitespace} | ( | ) | " | ;
{whitespace} --> {space or newline}
{comment} --> ; {all subsequent characters up to a line break}
{atmosphere} --> {whitespace} | {comment}
{intertoken space} --> {atmosphere}*
{identifier} --> {initial} {subsequent} *
| {peculiar identifier}
{initial} --> {letter} | {special initial}
{letter} --> a | b | c | ... | z | A | B | C | ... | Z
{special initial} --> ! | $ | % | & | * | / | : < | =
| > | ? | ~ | _ | ^
{subsequent} --> {initial} | {digit} | {special subsequent}
{digit} --> 0 | 1 | 2 | ... | 9
{special subsequent} --> . | + | -
{peculiar identifier} --> + | - | ...
{boolean} --> #t | #f
{character} --> #\ {any character}
| #\ {character name}
{character name} --> space | newline
{string} --> " {string element}* "
{string-element} --> {any character except " or \}
| {backslashed}
{backslashed} --> \ {any character}
{bit-string} --> {hex-bit-string} |
| {binary-bit-string}
{hex-bit-string} --> #H {hex-digit}*
{binary-bit-string} --> #B {binary-digit}*
{hex-digit} --> 0 | 1 | 2 | ... | 9
| a | b | ... | f
| A | B | ... | F
{binary-digit} --> 0 | 1
{number} --> {integer} | {real}
{integer} --> {sign} {digit}+
{sign} --> + | - |
{real} --> {sign} {digit}+ {decimal-part} {exponent}
{decimal-part} --> . {digit}*
{exponent} --> e {sign} {digit}+
The external representations of Scheme objects, datums, are formed according to the following grammar:
{datum} --> {simple datum} | {compound datum}
{simple datum} --> {boolean}
| {number}
| {character}
| {string}
| {bit-string}
| {symbol}
{symbol} --> {identifier}
{compound datum} --> {list} | {vector}
{list} --> ( {datum}* ) | ( {datum}+ . {datum} )
| {abbreviation}
{abbreviation} --> {abbrev prefix} {datum}
{abbrev prefix} --> ' | ` | , | ,@
{vector} --> #( {datum}* )
The expression syntax for the compiler is specified in the grammar below. As opposed to that in [1], we do not give syntax for most of the derived expressions due to the fact that they are implemented using the macro system and thus their grammar is not a part of the compiler per se. Concerning quasiquotations, see the note in [1] about the grammar formalism.
{expression} --> {variable}
| {literal}
| {procedure call}
| {lambda expression}
| {conditional}
| {assignment}
| {sequencing}
| {compiler directive}
| {syntax}
{literal} --> {quotation} | {self-evaluating}
{self-evaluating} --> {boolean}
| {number}
| {character}
| {string}
| {bit-string}
{quotation} --> '{datum} | (quote {datum})
{procedure call} --> ({operator} {operand}*)
{operator} --> {expression}
{operand} --> {expression}
{lambda expression} --> (lambda {formals} {body})
{formals} --> ({variable}*) | {variable} |
| ({variable}+ . {variable})
{body} --> {sequence}
{sequence} --> {command}* {expression}
{command} --> {expression}
{conditional} --> (if {test} {consequent})
| (if {test} {consequent} {alternate})
{test} --> {expression}
{consequent} --> {expression}
{alternate} --> {expression}
{assignment} --> (set! {variable} {expression})
{compiler directive} --> (include {string})
{sequencing} --> (begin {sequence})
{quasiquotation} --> {qq 1}
{template 0} --> {expression}
{qq D} --> `{template D}
| (quasiquote {template D})
{template D} --> {simple datum}
| {list template D}
| {vector template D}
| {unquotation D}
{list template D} --> ({template or splice D}*)
| ({template or splice D}+ . {template D})
| '{template D}
| {qq D+1}
{vector template D} --> #({template or splice D}*)
{unquotation D} --> ,{template D-1} | (unquote {template D-1})
{template or splice D} --> {template D}
| {splicing unquotation D}
{splicing unquotation D} --> ,@{template D-1}
| (unquote-splicing {template D-1})
{syntax} --> (let-syntax ({syntax-binding}*) {body})
| (letrec-syntax ({syntax-binding}*) {body})
{syntax-binding} --> ({macro-name} {literals} {syntax-pattern}+)
{macro-name} --> {variable}
{literals} --> ({variable}*)
{syntax-pattern} --> ({pattern} {template})
{pattern} --> {datum}
{template} --> {datum}
Finally, programs compiled by the compiler are defined by the following grammar:
{program} --> {command or definition}*
{command or definition} --> {command} | {definition}
{definition} --> (_define {variable} {expression})
| (begin {definition}*)
| (define-syntax {macro-name}
{literals}
{syntax-pattern}+)
The semantics of the source language is that of the Scheme programming language with extensions. The following noteworthy extensions exist:
- There is a global variable exception-handler that can contain a procedure that will be called when running programs receive messages.
- There is a procedure send-message that can be used to send messages.
- There are primitive procedures push-to-queue and get-from-queue that can be used to handle an internal message queue, so that get-from-queue will block if the queue is empty until an exception handler pushes more to the queue using push-to-queue.
The following primitive procedures are supported by the compiler:
Core procedure: (car pair)
Return the first item of a given pair.
Core procedure: (cdr pair)
Return the second item of a given pair.
Core procedure: (cons value value)
Create a new pair.
Core procedure: (set-car! pair value)
Set the first item of a given pair.
Core procedure: (set-cdr! pair value)
Set the second item of a given pair.
Core procedure: (make-tagged-pair tag)
Create a new tagged pair with the given tag.
Core procedure: (make-vector length)
Create a new vector of the given length.
Core procedure: (make-tagged-vector length tag)
Create a new tagged vector with the given tag and of the given length.
Core procedure: (vector-set! vector index value)
Set the indexth value of vector to value.
Core procedure: (vector-get vector index)
Return the indexth value of the given vector.
Core procedure: (vector-ref vector index)
A synonym to vector-get.
Core procedure: (make-shared-bit-string length)
Core procedure: (make-private-bit-string length)
Core procedure: (make-shared-bit-string length tag)
Core procedure: (make-private-bit-string length tag)
Create a new bit string whose length is LENGTH bits (not bytes).
Core procedure: (bit-string-length string)
Return the length of string in bits (not bytes).
Core procedure: (bit-string-shr string amount)
Core procedure: (bit-string-shl string amount)
Core procedure: (bit-string-rol string amount)
Core procedure: (bit-string-ror string amount)
Shift (shr/shl) or rotate (rol/ror) bit strings left or right; return newly allocated bit strings.
Core procedure: (bit-string-and string1 string2)
Core procedure: (bit-string-or string1 string2)
Core procedure: (bit-string-xor string1 string2)
Core procedure: (bit-string-neg string1)
Bit-wise bit string operations; return newly allocated bit strings.
Core procedure: (set-bit-substring! string1 string2 offset)
Copy the contents of string2 over string1, starting at the position offset.
Core procedure: (get-bit-substring string1 start length)
Return a newly allocated bit string that contains the region of string1 that starts at the startth bit and spans length bits.
Core procedure: (send-message address message)
Send a given message to a given address.
Core procedure: (not value)
Return #f if value is not #f, otherwise #t.
Core procedure: (eq? value value)
Return #t if two values are exactly the same object, otherwise #f.
Core procedure: (halt)
Terminate; commit a suicide; exit; quit; halt for ever.
Core procedure: (exit)
A synonym to halt.
Core procedure: (quit)
A synonym to halt.
Core procedure: (int+ integer integer)
Core procedure: (int/ integer integer)
Core procedure: (int- integer integer)
Core procedure: (int* integer integer)
Core procedure: (int= integer integer)
Core procedure: (int>= float float)
Integer arithmetics and comparison.
Core procedure: (float+ float float)
Core procedure: (float/ float float)
Core procedure: (float- float float)
Core procedure: (float* float float)
Core procedure: (float= integer integer)
Core procedure: (float>= float float)
Floating-point arithmetics.
Core procedure: (modulo integer integer)
Core procedure: (divide integer integer)
Core procedure: (remainder integer integer)
Number-theoretical division and remainders for integers.
Core procedure: (boolean? value)
Return #t if value is a boolean object, otherwise #f.
Core procedure: (integer? value)
Return #t if value is an integer object, otherwise #f.
Core procedure: (float? value)
Return #t if value is a floating-point number object, otherwise #f.
Core procedure: (pair? value)
Return #t if value is a pair, otherwise #f.
Core procedure: (vector? value)
Return #t if value is a vector of any length, otherwise #f.
Core procedure: (shared-bit-string? value)
Return #t if value is a shared bit string, otherwise #f.
Core procedure: (private-bit-string? value)
Return #t if value is a private bit string, otherwise #f.
Core procedure: (tagged-pair? value tag)
Return #t if value is a tagged pair and has the tag tag, otherwise #f.
Core procedure: (tagged-vector? value tag)
Return #t if value is a tagged vector of any length and has the tag tag, otherwise #f.
Core procedure: (tagged-shared-bit-string? value tag)
Return #t if value is a tagged shared bit string and has the tag tag, otherwise #f.
Core procedure: (tagged-private-bit-string? value tag)
Return #t if value is a tagged private bit string and has the tag tag, otherwise #f.
Core procedure: (procedure? value)
Return #t if value is a procedure object, otherwise #f.
The macro facility provided by the compiler is reminiscent of that proposed in [1]. With every macro, a set of literals and a set of syntax patterns is associated. The set of literals is a set of keywords that are recognized as literal identifiers as instead of pattern variables in a pattern. Syntax patterns are used to define actual macro transformations. The syntax of macro definitions is seen from the grammars presented previously.
A syntax pattern consists of a pattern and a template. When macro is expanded, the macro invocation is matched against the patterns in the order they appear in the corresponding macro definition. When a first matching pattern is found, the corresponding template is expanded and the expansion replaces the original invocation during the macro expansion process.
A pattern is a Scheme expression, where variables denote pattern variables that can be matched by arbitrary sub-expressions in the invocation. Ellipsis (...) can be used to denote repetition and works as in the appendix of [1]. Pattern variables appearing in the template get their bindings from the matching. Ellipsis can naturally appear in the templates too.
The compiler outputs an assembler source file. The structure of an assembler source file is defined in the grammar below. Low-level lexical conventions are those of Scheme; semi-colons start comments and the structure of white space is not important.
{asm file} --> {preamble} @instructions {instructions} @constants {constant}
{preamble} --> {register spec}*
{register spec} --> {asm identifier} {integer}
{instructions} --> {instruction or label}*
{instruction} --> ({operator} {operand}*)
{asm identifier} --> {start} {subsequent}*
{start} --> {lower-case letter or hyphen}
{subsequent} --> {start or digit}
{label} --> {asm identifier} :
{operator} --> {asm identifier}
{operand} --> {register} | {index} | {label}
{register} --> {asm identifier}
{index} --> {integer}
{constant} --> {vector spec}
| {boolean spec}
| {bit-string spec}
| {integer spec}
| {pair spec}
{vector spec} --> vector {length} {constant}
{boolean spec} --> boolean {0 or 1}
{bit-string spec} --> bit-string {length} {byte}*
{length} --> {integer}
{byte} --> {integer}
{integer spec} --> integer {integer}
{pair spec} --> pair {constant} {constant}
See the section on assembler for details.
The compiler can be executed from the UNIX command line, and the following options are recognized:
- --asmopts STRING
- Pass STRING to the assmbler when invoked as a sub-process of the compiler. Default is the empty string.
- --assemble, --noassemble
- Choose whether or not to run assembler. Default is to run.
- --assembler NAME
- Set the assembler executable name as given to a sub-shell starting the assembler (default is "ssasm").
- --help
- Output a help message and exit.
- --includedir DIR
- Add the directory DIR as the first to the list of directories to be searched for included files.
- --optimize LEVEL
- Set the optimization level, zero for no optimization at all and larger integers for more optimization.
- --verbose
- Make the compiler to print information about its progress. Can be given multiple times to get more verbosity.
- --trace ITEM
- Choose to trace a specific part of the compiler identifier by ITEM. This is for debugging only.
- --std, --nostd
- Choose to include or to not include the standard include files that define e.g. the derived forms of the Scheme language. The default is to include.
Non-option arguments on the command line are files to compile. If a file name ends with the suffix ``.ssscm'' or the suffix ``.scm'', the suffix is stripped of from the file name. A corresponding assembler file is always written and has the suffix ``.ssasm''. The byte code file created by the assembler has the suffix ``.ssbc''.
The [Scheme] implementation of the compiler is divided into the following parts:
COMPILER -- Main interface -- command line processing
| |
| - compiler invocation
| |
| - assembler invocation
|
- Scheme reader -- lexical parser
| |
| - datum building
|
- Macro expansion -- semantic tree building
| |
| - macro transformations
| |
| - lexical address resolving
| |
| - semantic optimizations
|
- Code generation -- linearization phase
| |
| - peephole optimizer
|
- Support
|
- General auxiliary procedures
Short descriptions of the components presented above follows.
- Main interface
- The Main interface module is responsible for interacting
with the user and the assembler. It consists of
- a command line processor, that interprets the command line given by the user and runs the compiler with the functionality requested in the line;
- a compiler invoker, that is used by the command line processor to invoke the real compiler; and
- an assembler invoker, that is used to interact with the external assembler when creating byte code object files.
- Scheme reader
- The Scheme reader module is responsible for reading and parsing
Scheme expression from input streams. It consists of two parts:
first,
- a lexical parser, that tokenizes an input stream, and
- a datum builder, that interprets a stream of tokens and builds structured data objects from the stream.
- Macro expansion
- The Macro expansion module is responsible for transforming a
Scheme program into a semantically equivalent semantic tree,
expanding user-defined macros during the process.
The Macro expansion module consists of
- procedures to create different semantic trees and to control the expansion process;
- procedures to define new macro transformers and to apply them;
- functionality to compute the static lexical addresses of variable references; and
- a sub-module that implements certain semantic optimizations after the mapping to a semantic tree has finished.
- Code generation
- The Code generation module transforms a semantic tree to
a byte code sequence. The code generation module consists of
- a linearization sub-module that implements the actual linearization, and
- a peephole optimizer that does final optimizations on the linearized code.
- Support
- The Support module contains procedures and sub-modules that are specific to the compiler but that cannot be easily fit into the modules above. These sub-modules include e.g. modules for keeping track of the lexical environments during compilation.
- General auxiliary procedures
- The Generaul auxiliary procedures include compiler non-specific
procedures that are handy in implementing the compiler but that
are not present in some standard Scheme implementations.
The main interfaces for the modules and implementation highlights will be specified and discussed next.
File compiler.scm
Scheme-functions:
- Function (current-build-info date builder host)
Description: Set the current build date to be DATE, the builder identifier to be BUILDER, and the building host to be HOST. This information is set for informational purposes only. If this function is not called, then all the variables (build date, builder identifier and building host) assume the default value "?UNDEFINED?". - Function (current-version-is version-string release-date)
Description: Set the current version identifier to be VERSION-STRING and the date of the current release to be RELEASE-DATE. This information is set for informational purposes only. If this function is not called, then both variables (current version and release date) assume the default value "?UNDEFINED?". - Function (run-compiler)
Description: Run the compiler. Read an argument list (a Scheme list of strings) from standard input, i.e. the current input port. After reading succesfully a list of strings, pass the list to run-non-interactive-compiler. - Function (run-non-interactive-compiler command-line-args)
Description: Parse the command line arguments given in COMMAND-LINE-ARGS and execute compiler functionality according to them.
File compile-file.scm
Scheme-functions:
- Function (build-tree-from-file source)
Description: Read a file with a given name and build a semantic tree from the source code it (hopefully!) represents. The return value is the semantic tree built or #f if an error was encountered but the procedure returned however. - Function (compile-file basename)
Description: Compile the file BASENAME.ssscm and output the resulting assembly language to the file BASENAME.ssasm. If assembler invocation is enabled, finally rut he assembler using run-assembler. Return value is unspecified. Errors are returned using the normal comerr procedure. This function is responsible for controlling the overall compilation process of a program.
- Function (compile-linearize-optimize tree)
Description: Linearize a semantic tree, with optimizations. This procedure assumes that certain compiler data structures contain data, corresponding to the tree, that are created in compile-transform-tree!. Thus this procedure should be called only for trees that have been created using compile-transform-tree! just previously. Returns an instructions sequence or #f if something went wrong. - Function (compile-transform-tree! tree)
Description: Do certain transformations for a semantic tree, in particular inline primitives and compute lexical addresses. The transformations are made destructively, i.e. the tree given as input is mutated (although to a better one!) The return value is the tree after mutations or #f is something went fatally wrong. It is possible that the root of the tree changes, so the return value must be used instead of TREE after he transformations have been made. - Function (output-and-assemble sequence basename)
Description: Write the symbolic assembler file corresponding to the byte code instruction sequence SEQUENCE to the file named BASENAME.ssasm. Also run the assembler if it is requested (not inhibited) by the options set. - Function (output-object-for-assembler object port)
Description: Output a Scheme object OBJECT to a certain output port. The object is outputted in a format that is understood by the external SchemeStation byte code assembler. - Function (reset-compiler!)
Description: Initialize compiler data structures for a new compilation project. - Function (run-assembler basename)
Description: Invoke the assembler. BASENAME is a file name without suffix. The file BASENAME.ssasm must exist. The external assembler is invoked using the assembler executable path name and assembler options possibly specified in the compiler command line. The return value is the return status of the assembler executable. If verbosity level is at least 1, output the assembler command line just before executing.
File file-input.scm
Scheme-functions:
- Function (read-file file)
Description: Read in the file FILE. Returns an annotated expressions. Implemented in the terms of read-from-port. - Function (read-from-port input-port stream-name)
Description: Read, using the compiler's Scheme reader, all expressions readable from the port PORT. STREAM-NAME is a descriptive name of the stream and is used if errors are encountered. The result value is an annotated expression, constructed such that if E1 ... EN are the N expressions read, the value returned contains (begin E1 ... EN). - Function (read-include-file file)
Description: Read in the include file named FILE, searching for it from the include path. Returns the expression found from the include file. If the include file cannot be found an error is signalled. - Function (safe-open-file filename)
Description: Try to open the file FILENAME and return a reading port if succeeded. If the file cannot be opened, return #f instead of the port.
File initial-lex-env.scm
Scheme-functions:
- Function (make-initial-lexical-environment)
Description: Create the initial lexical environment that will be in effect when the compilation of a program starts.
File options.scm
Scheme-functions:
- Function (options-error . args)
Description: Signal an error during [command line] options processing. First do (apply printf args), i.e. interpret the first argument as a format string and the rest as objects to format, and output the result to the current output port (usually standard output). Then call the function output-options-help-and-exit, which is not defined in the options module but must be provided externally. - Function (process-command-line-options options-list non-switch-callback!)
Description: Process the list of command line options OPTIONS-LIST, which may contain both switches and non-switch arguments (i.e. file names). For every argument that is not a switch nor an argument for a switch, NON-SWITCH-CALLBACK! is called as (NON-SWITCH-CALLBACK! COMMAND-LINE-ITEM) and the result of this procedure call is ignored. Recognized switches are processed. If an unrecognized switch is encountered or some other error happens during the processing, the SPROC(options-error) procedure is called. The set of recognized switches is exactly the set of registered switches. Switches are registered using procedures below. - Function (register-boolean-option names callback!)
Description: This is as register-option-callback, but registers a boolean switch that takes no arguments. CALLBACK! will be called with one argument that is either #t or #f. If a boolean switch has the name NAME, then the switch is recognized in four forms: -NAME, --NAME, -noNAME, --noNAME. The first two forms cause the callback to be called with the value #t and the later two with the value #f. The return value of the callback is always ignored. - Function (register-option-callback names num-args callback!)
Description: Register a switch with possibly multiple names. NAMES is a list of strings that are the names of the switch. NUM-ARGS is the number of arguments excepted by the switch, and CALLBACK! is a procedure that will be called to process the switch when it is found from the command line. CALLBACK! should be a procedure that accepts a call with NUM-ARGS arguments. When the callback is called any return value of the call is ignored. A switch with name NAME is recognized in two forms in the command line: -NAME and --NAME. Unambiguous [prefix] abbreviations are also recognized. Arguments may not be melted to the switch but must be separate command line items (i.e. --NAMEx nor --NAME=x will work, --NAME x must be used).
The Scheme reader used in the compiler reads in expressions but does not store them in the native way, but instead as annotated expressions. Annotated expressions are Scheme expressions that contain information about the source of the expressions. For example, the name of the file where the expression is originally read is stored as an annotation associated with the expression.
The lexical parser is generated using Danny Dube's SILex lexical scanners generator. See SILex documentation for interfaces and other details.
File reader.scm
Scheme-functions:
- Function (annotated-expr-annotation a-expr)
Description: Return the annotation part of an annotated expression. - Function (annotated-expr-expr a-expr)
Description: Return the expression part of an annotated expression. - Function (make-annotated-expr expr annotation)
Description: Create an annotated expression with the expression part EXPR and the annotation part ANNOTATION. - Function (make-port-reader port name failure-cont)
Description: Make a reader procedure that reads annotated expressions from the port PORT. Give the stream the name NAME, which will be added as annotation to the expressions read. FAILURE-CONT is a one-argument procedure that will be called if a read error happens. FAILURE-CONT must not return. FAILURE-CONT gets as its argument, when called, a list of length four, with the following items: (1) NAME, (2) current line number in the stream, (3) current column number in the stream, (4) current number of bytes read from the stream (i.e. total offset). The reader returned itself is a zero-argument procedure that either returns an annotated expression, returns the symbol 'eof, or calls FAILURE-CONT --- which must not return.")
File lexer.scm
Scheme-functions:
- Function (unbackslashify str)
Description: Return a newly allocated copy of the given string STR, parsing backslash sequences. \n is mapped to the newline character. For all other characters X, \X is mapped to X.
File st-application.scm
Scheme-functions:
- Function (build-st-application subtrees annotated-expr)
Description: Create a semantic tree denoting a procedure application.
File st-asm.scm
Scheme-functions:
- Function (build-st-asm annotated-expr
list-of-annotated-instructions)
Description: Build a semantic tree denoting an inlined sequence of byte code instructions. - Function (build-st-asm-closure annotated-expr
list-of-annotated-instructions)
Description: Build a semantic tree denoting an inlined sequence of byte code instructions and handled as a full closure.
File st-assign.scm
Scheme-functions:
- Function (build-st-assign var-tree val-tree annotated-expr)
Description: Create a semantic tree denoting an assignment.
File st-aux.scm
Scheme-functions:
- Function (build-st-error annotated-expr)
Description: Create a semantic tree denoting an error during the compilation process. - Function (error-tree severity annotated-expression format-string . args)
Description: Signal, via comerror, an error of severity SEVERITY in ANNOTATED-EXPRESSION, with additional information provided by FORMAT-STRING and ARGS (see comerror), and then return a semantic tree denoting an error, containing ANNOTATED-EXPRESSION.
File st-closure.scm
Scheme-functions:
- Function (build-st-closure variable-containers annotated-expr body-tree)
Description: Create a semantic tree denoting a (lambda) closure.
File st-literal.scm
Scheme-functions:
- Function (build-st-literal scheme-value annotated-expr)
Description: Create a semantic tree denoting a literal value.
File st-primitive.scm
Scheme-functions:
- Function (build-st-primitive-procedure procedure-specification annotated-expr)
Description: Create a semantic tree denoting a primtive procedure (the procedure itself, not its invocation.)
File st-sequence.scm
Scheme-functions:
- Function (build-st-sequence-from-body-list body-list lex-env shadow uncond?)
Description: Create a semantic tree denoting a sequence. BODY-LIST is a list of annotated Scheme expressions. However, the list itself must not be annotated (use remove-list-annotations).
File st-syntax.scm
Scheme-functions:
- Function (build-st-syntax syntax-procedure scheme-expr lex-env shadow uncond?)
Description: Create a semantic tree denoting the application of a macro defined via define-syntax.
File st-test.scm
Scheme-functions:
- Function (build-st-test test-tree conseq-tree altern-tree annotated-expr)
Description: Create a semantic tree denoting a conditional.
File st-variable.scm
Scheme-functions:
- Function (build-st-unbound-variable annotated-expr)
Description: Create a semantic tree denoting a reference to a variable that does not exist in the current lexical environment. (Later a binding for the variable is searched for from the global environment, but the global environment does not exist, naturally, yet when the semantic trees are created - Function (build-st-variable vd-container annotated-expr)
Description: Create a semantic tree denoting a reference to a variable.
File st-main-build.scm
Scheme-functions:
- Function (build-st annotated-scheme-expr lex-env shadow uncond?)
Description: Build a semantic tree corresponding to a given (annotated) expression. The semantic tree is built in the lexical environment LEX-ENV. The flag UNCOND? denotes whether or not the place of the current expression in the program is such that it will be evaluated in any case, not depending on conditionals or function applications. It is used to decide whether or not a global definition can take place. SHADOW contains information about lexical bindings that come to effect via macro invocations.
- Function (build-st-top-level annotated-expr)
Description: Build the semantic tree corresponding to the annotated expression EXPR, which denotes a whole top-level program.
File syntax-asm.scm
Scheme-functions:
- Function (syntax-asm annotated-scheme-expr lex-env shadow uncond?)
Description: Parse an inlined assembler expression. - Function (syntax-asm-closure annotated-scheme-expr lex-env shadow uncond?)
Description: Parse an inlined assembler closure expression.
File syntax-begin.scm
Scheme-functions:
- Function (syntax-begin annotated-scheme-expr lex-env shadow uncond?)
Description: Parse a begin-expression.
File syntax-define.scm
Scheme-functions:
- Function (syntax-define annotated-scheme-expr lex-env shadow uncond?)
Description: Parse a _define-expression (_define is the "rudimentary" define, provided directly by the compiler. The actual define form is implemented as a macro on the top of _define).
File syntax-if.scm
Scheme-functions:
- Function (syntax-if annotated-scheme-expr lex-env shadow uncond?)
Description: Parse an if-expression.
File syntax-include.scm
Scheme-functions:
- Function (syntax-include annotated-scheme-expr lex-env shadow uncond?)
Description: Parse an include compiler directive, reading in the included file recursively.
File syntax-lambda.scm
Scheme-functions:
- Function (syntax-lambda annotated-scheme-expr lex-env shadow uncond?)
Description: Parse a lambda-expression.
File syntax-quote.scm
Scheme-functions:
- Function (syntax-quote annotated-scheme-expr lex-env shadow uncond?)
Description: Parse a quote expression.
File syntax-set.scm
Scheme-functions:
- Function (syntax-set-define annotated-scheme-expr lex-env shadow define?)
Description: Parse an assignment (set!) expression.
File syntax-procedures.scm
Scheme-functions:
- Function (make-core-syntax-frame)
Description: Create a syntax frame where the core syntax constructs are bound to the procedures parsing them.
File macros.scm
Scheme-functions:
- Function (syntax-define-syntax annotated-scheme-expr lex-env shadow uncond?)
Description: Parse a define-syntax expression, defining new global syntax. - Function (syntax-let-syntax annotated-scheme-expr lex-env shadow uncond?)
Description: Parse a let-syntax expression, defining a new local syntax and then expanding the body in the new syntactic environment. - Function (syntax-letrec-syntax annotated-scheme-expr lex-env shadow uncond?)
Description: Parse a letrec-syntax expression.
Semantic optimization is not specified yet.
File lexaddrs.scm
Scheme-functions:
- Function (compute-lexical-addresses! semantic-tree)
Description: Add to the semantic tree SEMANTIC-TREE static lexical addresses for variable references and assigned variables. The function mutates the tree, and returns the tree after succesful execution. Errors are reported in a standard way using comerr.
File newlinearizer.scm
Scheme-functions:
- Function (linearize-program-tree tree)
Description: Examine the semantic tree TREE, denoting a whole program, and return a byte code instructions sequence that is the linearization of the tree.
File peephole.scm
Scheme-functions:
- Function (peephole-optimize! instruction-sequence)
Description: Make peephole-style optimizations on the given instruction sequence INSTRUCTION-SEQUENCE. The instruction sequence is possibly mutated during the process. An optimized instruction sequence is returned. The behaviour of the peephole optimizer can be affected by global options set e.g. in the command line arguments.
File comerror.scm
Scheme-functions:
- Function (compiler-exit-on-error-function arg)
Description: compiler-exit-on-error-function is called when a fatal error has been signalled. It can be redefined to produce whatever behaviour needed. The default is to signal error to the underlying Scheme. When a binary dump of the compiler is made, this function is redefined to exit immediately from the program. - Function (icomerr . args)
Description: Report an internal compiler error. This causes a fatal compiler error to be reported. ARGS are outputted verbatim in the error message and need not to be very user friendly. After all, internal compiler bugs should not exist in the final product.
File global-vars.scm
Scheme-functions:
- Function (define-global-variable! name)
Description: Define a new global variable NAME in the global environment of the currently compiled program. - Function (global-variable-index var-name)
Description: Return the index of the defined global variable VAR-NAME. - Function (implement-closed-primitive! name specs)
Description: Require the primitive procedure SPECS to be implemented as a real closure, which is then bound to the global variable NAME. - Function (is-defined-global-variable? var-name)
Description: A predicate to test whether the name VAR-NAME is already defined in the global environment or not. - Function (num-global-vars)
Description: Return the number of currently defined global variables. - Function (print-global-variables-table output-port)
Description: Output the contents of the global variables table in a form suitable to be inserted to an assembler file as an informative comment.
File lexical-bindings.scm
Scheme-functions:
- Function (find-lexical-binding scheme-expr lex-env)
Description: Find the lexical binding for the variable SCHEME-EXPR in environment LEX-ENV. Return the binding found or a binding that denotes an unbound value, if no binding was found. - Function (lexical-binding-type binding)
Description: Return the type field of the lexical binding BINDING. - Function (lexical-binding-value binding)
Description: Return the value field of the lexical binding BINDING. - Function (make-lexical-binding name type value)
Description: Create a lexical binding object that denotes binding the variable NAME to an object of type TYPE and value VALUE.
File trees.scm
Scheme-functions:
- Function (dump-tree-to-port tree port)
Description: Output a graphic representation of the semantic tree TREE to the port PORT. - Function (make-leaf-node properties)
Description: Create a new tree node without subtrees, i.e. a leaf node. - Function (make-node properties subtrees)
Description: Create a new tree node with properties PROPERTIES and subtrees SUBTREES, which should be a list. - Function (node-properties node)
Description: Return the properties of the tree NODE. - Function (node-property node property)
Description: Return the value of the property PROPERTY in the node NODE. If the property is not set, return the default value #f. - Function (node-set-subtrees! node subtrees)
Description: Set the subtrees of the tree NODE to SUBTREES, destructively. - Function (node-subtrees node)
Description: Return the subtrees of the tree NODE.
The pretty printer used in the SCHEMESTATION compiler is written originally by Marc Feeley in 1991. It is modified slightly to fit our purposes.
[The printf family is again home-made.]
File printf.scm
Scheme-functions:
- Function (pprintf port str . args)
Description: As printf, put print to PORT instead of (current-output-port). - Function (printf str . args)
Description: Interpret STR as a format string, and output to the current output port STR verbatim, except for certain control sequences that start with the percent sign (%) and are replaced with renderings of the rest arguments ARGS in order. The general form of a control sequence is %[justification-flag][width]{format-char}. justification-flag and width are optional, format-char is mandatory. format-char is one of the following characters: (1) 'd', denoting that the corresponding argument is rendered as if outputted using the procedure display, (2) 'w', denoting that the corresponding argument is rendered as if outputted using the procedure write (i.e. in a form understood by Scheme's read), (3) 'p', denoting that the corresponding argument should be pretty-printed, and (4) 'a', denoting that the corresponding argument is an annotated expression and should be written as if 'w' had given but with the annotations data removed. The width field is used to control the exact length of rendered string. If no width field is present, then the whole string representing the corresponding object is outputted in its natural length. If a width field is present, then the representation will be modified to use exactly the amount of characters specified by the width field. The width field controls the width of pretty printing if the format 'p' is used, not the length of the renderation (this is an exception).
The justification-flag field has no effect if width has not been specified. If width has been specified, then the justification-flag controls the alignment of text in the rendered string if the text is shorter than the requested width. Three flags are understood: (1) 'l', meaning to align to left, (2) 'r', meaning to align to right, and (3) 'c', denoting centering.
- Function (sprintf str . args)
Description: As printf, put return a string instead of outputting to a port.
File trace.scm
Scheme-functions:
- Function (enable-trace! tracing-mode)
Description: Enable the tracing mode TRACING-MODE. By default, all modes are disabled. Tracing modes are enabled to get useful information about the internal workings of the compiler, mainly for debugging purposes.") - Function (trace-printf tracing-mode . args)
Description: Do (apply printf ARGS) if the tracing mode TRACING-MODE has been enabled, otherwise do nothing. The return value is unspecified.") - Function (verbosity-printf verbosity-level . args)
Description: Do (apply printf ARGS) if the compiler verbosity option is at least VERBOSITY-LEVEL, otherwise do nothing. The return value is unspecified.")
The assembler, written in C, reads in assembly files and outputs byte code objects.
The general input syntax of the assembler is specified previously [see above] but is elaborated on here.
Every instruction is presented with an expression of form
(
Registers are specified using symbolic names. The mapping of symbolic names to register numbers can be changed in the preamble. If no mapping is given, the following default mapping is used:
| Symbolic name | Register number |
| env | 0 |
| arg | 1 |
| cont | 2 |
| genv | 3 |
| t1 | 4 |
| val | 5 |
| t2 | 6 |
| t3 | 7 |
| t4 | 8 |
| t5 | 9 |
| t6 | 10 |
| t7 | 11 |
| mq | 12 |
| exc | 13 |
| stack | 14 |
| pc | 15 |
If at least one register identifier specification appears in the preamble then the default mapping is not used at all.
The constants part specifies one Scheme object, that must be a vector. The constants part must present a loopless Scheme object that is read then in in a depth-first manner. Vectors are specified by giving the vector keyword, then the vector length, and then as many constants as specified in the length field; similarly for other types (see the syntax).
The assembler needs to perform the following operations:
- Create binary byte code instructions from the symbolic instruction specifications;
- make constants table entries for labels and assign them; and
- output the resulting byte code instructions sequence and the constants table in a format understood by the SCHEMESTATION simulation.
Thus the implementation can be divided into the following parts:
ASSEMBLER -- Main interface -- command line processing
|
- Parser -- general lexical scanner
| |
| - instructions reading
| |
| - constants table reading
| |
| - preamble parsing
|
- Labels handling -- constants table entry allocation
| |
| - offset computation
|
- Binary data generation -- instruction generation
| |
| - constants table writing
|
- Aux & support
Short descriptions of the components presented above follows.
- Main interface
- The Main interface module is responsible of communicating with the
user and controlling the assembling process. It consists mainly of
- a unit for parsing the command line options [this is got from the SCHEMESTATION utilities library]
- Parser
- The Parser module is responsible for interpreting the
assembler files presented to the assmbler. It consists of
- a lexical scanner that tokenizes the input;
- a module for reading the instructions part;
- a module for reading the constants table; and
- a module for parsing the preamble.
- Labels handling
- The Labels handling module is responsible for allocating constant table entries for labels and computing their offsets.
- Binary data generation
- The Binary data generation module is responsible for creating the actual binary representation of the source program and storing it into a UNIX filesystem file. This module is implemented by using the SCHEMESTATION virtual machine and heap libraries, specified elsewhere.
- Aux & support
- Any other required [auxiliary] functionality is implemented in the Aux & support module.
The main interfaces for the modules and implementation highlights will be specified and discussed next.
Interface: int main(int argc, char **argv)
This is the main entry point of the program. It parses the command line using the SCHEMESTATION utilities library, and then assembles the files specified at the end of the command line.
Interface: void init_assembler(void)
This function is called before actual assembling starts. It initializes dynamically allocated memory structures required by the assembling procedure. This procedure should be called only once.
Interface: Status assemble(char *filename)
The string FILENAME is a file name without any suffix. The file FILENAME.ssasm is tried to assemble to the file FILENAME.ssbc. Returns STATUS_FAILED if the files cannot be opened, or if assembling failed. Otherwise outputs a byte code object to FILENAME.ssbc and returns STATUS_OK. This function may be called multiple times.
Interface: Status run_assembler(FILE *input, FILE *output)
Run the main assembler, reading data from INPUT and writing the byte code file to OUTPUT, if no errors occur. This is the core of the assembler, responsible of reading in the preamble, the instructions, the constants table, and then producing the byte code file.
The general algorithm is as follows: The generated lexical scanner is used first to read the preamble. When the preamble/instructions separator @instructions has been read, switch to an instructions reading mode. This mode is implemented as a simple state machine that adds instructions and labels read to dynamically growing tables using procedures defined below. When the instructions/constants separator @constants has been read, first label offsets are computed as now all labels should be defined. Then a dedicated procedure is used to read in the constants table. When the constants table has been read, the byte code object file is outputted and the assembling ends in success.
Interface: int get_instr_num(char *instr_name)
Return the instruction number corresponding to the symbolic instruction name INSTR_NAME. Return -1, if the instruction name is unknown.
Interface: int get_reg_num(char *reg_name)
Return the register number corresponding to the symbolic register name REG_NAME. Return -1, if the register name is unknown.
The lexical scanner used is generated using flex(1). See flex documentation for more information.
The following procedures are used to create labels and instructions, and to handle them:
Interface: void add_label(char *label_name, int *num)
Define a new label with the name LABEL_NAME. Return an index number for the label in NUM. This function always succeeds (unless the main memory is exhausted, but this is not taken into account).
Interface: int get_label_num(char *label_name)
Return the index number of the label named LABEL_NAME, or -1 if the label name is unknown.
Interface: Status set_label_denotation(int label_num, int instr_num)
Set the label number LABEL_NUM to denote the instruction INSTR_NUM, from the beginning of the program. Return STATUS_OK if the label had no previous denotation. If the denotation tried to set twice for the same label, the second (and subsequent) time(s) return STATUS_FAILED and do nothing.
Interface: Status compute_label_offsets(void)
Compute the real label offsets into the byte code sequence. These are not, in general, the same as the instruction numbers given in set_label_denotation, as the length of binary representations of byte code instructions vary depending on the complexity of the instructions.
Interface: Status build_linearized_object_vector(uchar **ptr, int *lenptr)
Build the byte code object (in essence, a linearized heap vector). The byte code object is allocated dynamically, and a pointer to it is written *PTR. The length of the object is written to *LENPTR. Return STATUS_OK, if everything went well. If something went wrong, return STATUS_FAILED. If the return value is not STATUS_OK, then PTR and LENPTR might contain garbage.
At the start of the procedure, a heap is initialized using the SCHEMESTATION heap library. This heap is utilized by the procedures below.
The algorithm used to implement build_linearized_object_vector is the following: first, initialize a heap. Allocate the binary object top-level vector from the heap. Then, read in the constants table and build the corresponding Scheme object, storing it in one slot of the binary object vector. Then build the binary representation of the instruction sequence and make a heap bit string from it. Store the bit string in one slot of the binary object vector. Then linearize the binary object vector, deinitialize the used heap and return the linearized heap, which is the binary code object.
Interface: Status build_constants_table(HeapTypedData *d1)
Read in the constants table and return the read constant object in D1. Return STATUS_FAILED if there was a syntactic or semantic error in the constants table.
The constants table is read in recursively. First, topmost object specification is read and it is ensured that it is a vector (the constants table must be a vector). Then read_constant() is called to read the items of the vector; read_constant() then calls itself recursively when reading composite data (pairs or vectors). In addition to the items readed from the file, also the label offsets are written to the actual constants table created. Thus the actual length of the constants table created is at least that of that in file, plus the number of distinct labels in the program.
Interface: Status read_constant(HeapTypedData *d)
Recursively read constants in, return result in *D. This is done according to the constants table syntax.
Interface: create_byte_code(unsigned char **bufptr, int *len)
Create the binary representation of the byte code sequence and return a pointer to a piece of dynamically allocated memory containing the binary representation in *BUFPTR. Return the length of the representation in *LEN. Return STATUS_OK if everything went ok, otherwise STATUS_FAILED, in which case BUFPTR and LEN might contain garbage.
Interface: build_instruction(int number, int *len, unsigned char *buf)
Write the binary representation of the instruction number NUMBER in the sequence to *BUF, if BUF is not NULL. Return the length of the representation in any case in LEN. This procedure utilizes the SCHEMESTATION virtual machine library. It is called twice, first to compute the label offsets but not to create any byte code, and then to create the actual binary representation.
Some auxiliary procedures will be needed, but they are not specified here.
- [1]
- William Clinger and Jonathan Rees (editors).
Revised4 Report on the Algorithmic Language Scheme.