1 Purpose
The purpose of this document is to describe how technical documents
are written in the
SCHEMESTATION project.
2 Creating documentation
2.1 Writing
- Documents are written into files that have ".ssdoc" as the
name suffix.
- Documents are written in HTML with the following changes:
- Lines starting with percent sign (%) are treated as comments.
However, precent signs in other places than
at the beginning of a line are not understood as comment characters.
- There are no html, head nor body tags.
Just do not use them.
- The first line of the document should contain the
tag <status document-status> where
document-status is a string that describes the status
of the document. Try e.g. "draft" (without the quotes).
- The title of the document must be given after the status line.
It is given using the normal HTML syntax for document title.
However, the whole title with the opening and closing tags must
fit on one physical line (that has no length limit, though).
Note:It is now possible to define a category for the
document. The category should be given with the following syntax:
<title technical>(title)</title>,
where the word technical is the desired category. Documents
with no category will default to the category "general". Please have a
look to the categories section for more
information on categories.
(The syntax may be cumbersome, but there was no easy way to patch
builddocs to recognize a cleaner one due to the line-by-line approach
adopted in the early phases of builddocs evolution.)
- You may use the tag <sindex key
"item"> to create an entry in the global index.
key is used to sort the entries and items appear in the
actual index. Dots (.) at the start of item are translated to
tabs in order to allow for multiple-level indexing.
- You may insert automatically generated C- or scheme code
module interface documentations in the document. The documentations are
generated by code-browser described in Code-Browser Utility. The
utility will recursively travel the filesystem beginning from
given root(s). It will parse the C header files and scheme files found
in the sub-directories. The function definations and data structures
(not implemented yet) will be in code-browser's internal index along
with the descriptions found in comments. More specific target in the
refered document may be specified with <ssref doc#place>, where place
would be the referred section of the document.
The browser recognizes standard C (ansi) and scheme syntax so that it can
find the function definitions and data structures. The code must be
under certain root-director{y,ies} so that it can be found during the
file traversal. To make it possible to find the function descriptions,
they have to placed in a comment straight before the definition of the
function both in scheme files and C header files.
The generated documentation can be using the tag <headers name
file1,file2,...>, where name is the name of the module
(that will appear as a <H1>-header) and files the C-header or
scheme files to be traversed.
The function descriptions consists of the name of the function (the
name is also a link to the code browser representation of the
source. It also contains the arguments, return value, and the
description that is captured from the comment preseding the function
definition in the header/scheme file.
You can reference the functions in text by using
<func>functionname</func>-tags. This generates a link to
the corresponding function description. To maintain the outlook of the
documentation, one should use <x>functionname</x>-tag to
use courier-type font.
- You may typeset mathematics using the construct
<math> LaTeX math commands </math>.
Both math tags must be on lines of their own. Here is an example:
<math>
a^2 + b^2 = c^2
</math>
results in
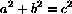
- XFig drawings can be incorporated into the document by using the syntax
<xfig "filename">. If you add another
quoted string after the filename it is presented as a caption.
- Lines with only whitespace (empty lines) generate <p> tags, much
as LaTeX does.
- The documentation source files are run through the M4 macro processor.
The quote tokens of the macro processor are changed to
{{ and }} and comments are disabled. All default M4 macros
are prefixed with m4_ (the macro processor is run with the -P flag set).
So, as an example, you could write something like
m4_define({{foo}},{{barf $1!}})
foo(zappa)
and get in the resulting HTML file "barf zappa!". See the documentation
of the M4 macro processor for more information.
- References to other SCHEMESTATION documents should be made
using the tag <ssref filename-prefix> where
filename-prefix is the name of the file to refer to,
without the .ssdoc suffix. This tag will be replaced
with the title of the document working as a hyper link.
So you should not write the title explicitly when using this tag.
Example:
The aids for documenting are
explained in <ssref documents>.
2.2 Processing
The script builddocs is used to create actual HTML files from
the .ssdoc files with the syntax above.
Run builddocs in a directory that contains all the
.ssdoc files. The resulting HTML files will be created in the
same directory along with some GIFs when necessary (resulting from
rendering math in LaTeX and incorporating XFig figures).
builddocs keeps track of the files it has created (or removed)
in a data file named builddocs-data in the current directory.
If you remove it accidentally
nothing extremely bad happens, but it is nevertheless not recommendable.
builddocs supports the following command line flags:
- --clean
- Cause builddocs to remove all files it knows it has generated
and then exit succesfully.
- --export SPEC-FILE
- Cause builddocs to export a certain subset of documents
according to the specification found from the file SPEC-FILE;
see below.
- --force
- Cause builddocs to remake all external figures without
further consideration.
- --install DIRECTORY
- Cause builddocs to install all files it has generated (i.e.
all documentation in HTML form) to the user-supplied directory DIRECTORY,
after first generating the files.
- --nopics
- Do not create any external pictures but write [FIGURE/MATH OMITTED]
on the appropriate places. Speeds up things. Does not mix well
with --force.
- --only BASENAME
- Build only BASENAME.ssdoc. Indices etc. are not recreated.
Suitable for previewing a document under work.
2.2.1 Categories
Due to the exponential growth the amount of stuff that has been
produced it will be more convenient for the possible reader to
organize the documents. The strategy outlined here is one proposed
solution for the problem.
From now on, the documents will be divided in categories. There can be
unlimited amount of categories, but the hierarchy can be only one
level deep (that is, in the current implementation.) The category in
which the document falls in is defined with the title-tag.
For every category, a new subdirectory will be made. The produced
html-files will be put into that very directory, along with a index
file that possesses a link to every document in that category. A
global index file will be produced in the parent directory of these
subdirectories.
It should be easy to copy or move these directories to wherever the
httpd expects, which may (provided that the categorization is very
smart) make the export strategy obsolete.
.builddocsrc
The categories are specified in the .builddocsrc-file. While
this is strictly speaking redundant - the categories could be created
dynamically as they occur in the title-tags - it may provide some
protection against typos, since categories differing by, say, a single
letter will not be created.
The syntax for the file is as follows:
course:subdir=course,title=Course related documents
First comes the name of the category which should be the same that
will be specified in the title-tag. Next are the attribute-value pair
separated by a colon. The recognized attributes are subdir (the
directory where the html-documents are put) and title (title to appear in
the per category index file).
2.2.2 Exporting subsets of documentation
builddocs allows you to export a subset of your documents
to a specified directory. To accomplish this, you need to write
an export specification file that tells the script what documents
to export and how.
The file is parsed on line-by-line basis. Every line is one
of the following:
- region start
- region end
- region text
- file specification
- target specification
- command
- ignored line (all others that cannot be recognized as one of the ones
above)
2.2.2.1 File specifications
File specification is of form
file BASENAME
and specifies that the document BASENAME (whose source is in
BASENAME.ssdoc) should be exported.
2.2.2.2 Target specification
Target specification is of form
target DIRECTORY
and specifies that the installation should take place to
the directory DIRECTORY. It is mandatory to specify a target.
2.2.2.3 Regions
Regions are used to specify arbitrary text that will be inserted
into the index page of the document distribution.
Region start is of form
region NAME
where NAME should be one of the following: head, title,
tail and beforeindex.
Region end is of form
end-region
All text between a region start and a region end or another region
start is region text. The index page is built then as follows:
[head]
[title]
... documents listing ...
[beforeindex]
... index ...
[tail]
where [NAME] refers to the region text of the region named NAME.
If index is not generated, then the region text ``beforeindex'' is not
inserted. Index is not generated by default. You can toggle whether
or not index will be generated, see below.
2.2.2.4 Commands
A command is a simple optional one-word command. Currently
the following commands are recognized:
- makeindex
- Generate index (the default is do not generate)
- omitstatus
- Don't show the status of the documents on the index page
2.2.2.5 Example of an export specification file
Here is an example of an export specification file:
region title
<H1>ZAPPA</H1>
end-region
omitstatus
file registers
file codingpolicy
file documents
target /home/antti/public_html/fozbaz/
This file specifies that three documents should be exported
(registers, codingpolicy, documents) to the directory
/home/antti/public_html/fozbaz/. One region is specified (title);
the string ZAPPA will be shown as a first-level heading before
the documents listing.
Other regions assume their default texts, which are reasonable.
The ``omitstatus'' command removes document status information
from the index page.