This document (along with several separate per module documents) specifies the algorithms, data structures and interfaces used in the SCHEMESTATION operating system simulation. The purpose of this document is to specify the implementation accurately enough to make programming the first prototype a fairly simple (but lenghty) task.
We have already divided the implementation into separate modules in [SchemeStation Functional Specification]. This document (along with the per module subdocuments) refines this division and specifies the inter-module interfaces in detail. Furthermore, we describe the requirements, functionality, and data structures of each module. Also, a declaration and description of essentially every noteworthy function can be found in the subdocuments.
There is a separate document of the terms used in the documentation of this project [Terminology specifications].
The document is structured as follows:
- The introduction briefly describes what this document should include and in which detail.
- The description of the system architecture describes how the system is divided into modules as well as the overall architecture of the system. It also summarizes briefly the functionality and purpose of each module.
- The module interface specifications and overall descriptions -section describes the interfaces, requirements, functionality and most important algorithms and data structures in brief for each module. This information is divided into per module subdocuments.
- The module implementation descriptions -section describes the implementation of each module. We have written a description for almost every function. This information is divided into per module subdocuments.
- The documentation, source code conventions and structuring includes a brief discussion about the conventions and tools we've used.
- The summary tries to represent all this briefly.
The objective of this project is to implement simulation of SCHEMESTATION operating system. The operating system itself is described in [Operating system specification] and the simulation in [SchemeStation Functional Specification]. The latter is summarized in [Section "Summary" in "SchemeStation Functional Specification"].
The SCHEMESTATION simulation will be run as a user-level process in an UNIX-environment. The requirements for the UNIX-environment were specified in Section "portability" in "SchemeStation Functional Specification". We develop the system on an PC running Linux, but it will be portable to the major UNIX-systems.
The base system is written in C. It uses the standard UNIX networking functions - the SCHEMESTATION networking is simulated on TCP/IP. The terminal uses X-library functions, which implies that launching a terminal requires access to a workstation with a X-server.
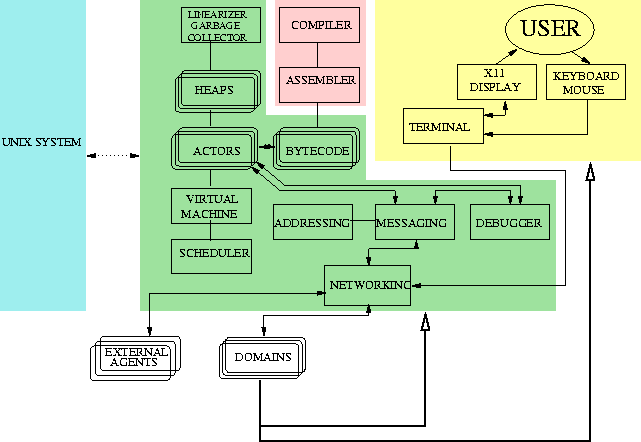
The implemention of the system is divided into several modules, each having their well-defined interfaces. The requirements of each module have been carefully specified first as a part of the overall system and then more accurately by the person or persons responsible for implementing the module.
More specific discussion on the system architecture presented by the above figure can be found in [Section "gendesc" in "SchemeStation Functional Specification"].
The virtual machine is implemented as a library - it has no internal state. Instead, its execution function is called with the executed bytecode as an argument as well as the heap and register set of the agent.
The execution funtion then executes the specified number of instructions, and returns the resulting status of the agent. Refer to [Virtual machine layout and interface definition] for further details.
[9] has been a good source of information in the design process of the virtual machine.
The scheduler will also be accomplished as its own module; its interface and implementation is specified in [Scheduler definition].
[3] has been a good source of information in the design process of the scheduler.
[7] has been a good source of information in the design process.
The address system maintains a hash table of agent entries to enable fast agent address lookups based on the specifier. More elaborating description of the module can be found in [Addressing module specification] and [Addressing module implementation].
The hash table concept used in the addressing system was adapted from [12 and 8]. Again, the design of addressing system involved studying [3].
The messaging system then consults the addressing system to find out whether the recipient agent resides in the local domain or a remote domain. If the recipient is a local agent, the message is put into the agent's message queue (in the addressing system), and the messages in the queue are passed to the virtual machine until the virtual machine sets the agent into blocking state or the queue becomes empty.
The blocking bit is in the agent entry in the addressing system. The virtual machine has to explicitly re-enable message receiving for an agent, which it does by calling the appropriate function in the messaging system. The messaging system then consults the addressing system to find out which entries map to that agent and sets their blocking bits to the non-blocking state.
If the message was sent a remote domain in the first place, the addressing system passes it to the networking system, that saves it to the queue of the corresponding connection.
Although message system may sound complicated, a lot of the functionality actually takes place in other modules, and the functions in the messaging system are fairly straightforward. It is, nevertheless, convenient to separate the implementation to its own module. More detailed documention on the messaging system may be found in [Messaging System Specification] and [Messaging System Implementation].
The network system is responsible for handling the inter-domain connections. The Operating system specification states, that the communication between domains (and moreover, between actors) has to be reliable. In this simulation this is ensured simulating the network traffic on TCP/IP. We thereby guarantee that the messaging is reliable if the underlying UNIX system and the underlying IP-network works normally.
In the usual networking scheme one SCHEMESTATION domain acts as a router (in the current implementation the router is a domain; there is no actual need for the router to be a domain), and all other domain open a TCP connection to it at the boot-up time. The router listens to a specific TCP-port and accepts connections from the client domains.
Both the router to connect and the command to act as a router are specified by a command line argument. There is an option in the networking module to maintain several connections; this option is used when acting as a router. It would also be possible to configure the SCHEMESTATION domains to connect to each other directly, but this practice is not officially supported. The networking module registers (all) the socket file descriptor(s) to the event loop at start-up time. In the router mode, also the listening socket is registered.
The event loop then calls the callback function whenever there are messages to read, a new connection opened or a possibility to send messages to a connection is presented. The networking system finds the appropriate connection from its connection list, and either receives the message (or part of it, if the connection blocks), sends messages from the connections queue, or adds the new connection to the list. Whenever a complete message is received, it is passed to the messaging system, and whenever a complete message is sent, it is removed from the queue.
For each new connection a handshake protocol is executed. If the handshake succeed, then both peers support the SCHEMESTATION protocol and the connection is agreed to be open.
The networking system is naturally a separate module, and its interface and implementation documentation can be found in [Networking Specification] and [Networking Implementation].
Many principles of the networking system protocols design were adapted from [6 and 10]. In the implementation design phase [7] has been valuable.
The heap module implements the structured memory system. The heap is implemented as list-organised, typed, garbage-collected system to support the ease-of-use targets of the Schemestation project. Heap can be linearised and linearisations can be returned to non-linearised form. This eases message-passing implementation at other modules.
The heap is typed - type of each object can be found out at run time. Instances of each object type can be created, manipulated and read using legal operations of their type domain.
The heap is garbage-collected - data unreachable from the "root set" (and, thus unreachable from any client reference) is automatically removed from time to time. The heap size is dynamic - only actual system memory exhaustion can cause failed memory allocation.
More description on the implementation, interface and the requirements of the heap module can be found in [Heap Module Specification].
The SCHEMESTATION cross compiler is used to produce, in combination with the SCHEMESTATION assembler and a procedure library, binary byte code objects that can be run by the SCHEMESTATION simulation. The compiler and the assembler are specified in [Compiler technical specification]..
Most of the basis of the compiler design have been adopted from [2, 1, 4 and 11].
Apart from the internal modules, C libraries will be implemented to make it possible for programmers to develop programs and extensions.
The external agents are merely any unix programs that connect to the SCHEMESTATION domains and can be seen as agents in the SCHEMESTATION system. The external agents obey the SCHEMESTATION external agent protocol in their communication with the domain. To make programming external agents convenient, we supply a C library that implements all the functions necessary to connect and communicate with a domain. In essence this means wrapping the event loop and networking module to a library and providing a straightforward interface to them.
We have considered providing the external agent interface a convenience for performance reasons, but since it is not strictly necessary for the functionality of the core system (or the whole simulation), its design and implementation is scheduled to start only after the core system is up and running (Recall that we have abandoned the water fall model in this project because of these kinds of issues.). We will supply more detailed information of the interface and the library as soon as the design begins.
The simulation will use the external agent scheme to implement some features one expects an operating system to offer. Since it might be somewhat inefficient to implement storing objects (files, data, whatever they should be called) in agents (recall that agents are persitent so that this would actually be possible), the unix file server will be implemented as an external agent. In essence, it connects to a domain using the SCHEMESTATION external agent protocol and library and stores the objects to UNIX files. There will be a native SCHEMESTATION agent that acts as interface to the server - its purpose is to implement the security and object naming functions.
The object server is considered to more an application than a part of the operating system. Due to this, its implementation and detailed design has not yet been completed. We will provide more detailed information on the requirements, implementation and other aspects of the object server as soon as we have finished the core system.
We have written a separate specification document on each module. These documents explain the overall structure of each module, define the interface to it and specify the requirements for the documents.
These documents include
We have written a separate implementation document on each module. These documents describe the used algorithms, data structures, as well as the internal functions (not included in the interface).
These documents include
- Networking Implementation
- Addressing module implementation
- Scheduler definition
- Messaging System Implementation
- Virtual machine layout and interface definition
- Heap Module Specification
- Compiler technical specification
There is a separate document on testing the modules and the system [Project Test Plan].
In addition to the actual system the project involves documenting and developing some additional tools. Also, the source code tree structure, coding conventions, and such have to be specified.
We use the CVS version control program to synchronize and control the development. We have decided that all the actual source code resides in the /src directory under the SCHEMESTATION root directory. In the /src directory, there is also the main Makefile, which recursively compiles all subdirectories. To achieve good portability, we use GNU Autoconf utility to make the configuration for each host. For further information on makefiles and related, see [Development environment of the SchemeStation project: makefiles and related].
Along with designing and coding, the most important task in this project is documentation. To reach both comprehensive documentation and good-quality of documentation, we have made a little utility that both expands some special tags and helps to gather the documentation from source files (see [Documentation]).
For the outlook and indentation of the source code, we have specified a project-wide standard. The definition can be found in [Project coding policy].
Getting familiar with a big project is always problematic, especially when the amount of source code to be read is high. To make it easier to get a clue from the system structure and to make it easy to search and browse the code, we have written a simple cgi-based perl system, the the code browser, that should make enable comfortable code browsing. Further detail can be found in [Code-Browser Utility].
In this document (and its subdocuments), we have described the structure of the SCHEMESTATION simulation implementation. Our implementation consists of several modules, namely the virtual machine, the heap, the compiler, the networking module, the messaging module, the addressing module and few other non-core modules, such as the event loop, and the terminal.
Due to the nature of the system, we have not adopted the water fall model. Instead, we have chosen to first implement the basic functionality of the system - which we call the core system.
We have so far specified and implemented the core system. Modules not belonging the core system - the terminal - have not yet been completely specified. Moreover, the event loop that has been implemented by SSH Communications Security Oy, has not been specified, since we did not have to design it [Section "ssh" in "Project Test Plan"].
For the core system modules, we have written a specification paper, implementation paper (for some modules these are the same) and a testing plan paper. The specification paper specifies the requirements, interface and some implementation outlines. The intention has been that based on the specification paper, it would be possible to reimplement the module. The implementation paper describes our implementation in in detail - essentially every function is described along with the data structures and used algorithms.
It is inconvenient to get into more details here when it comes to per module specifications and implementations. The Description of the system architecture -section should give, while being comfortably brief, a good picture of the functionality of each module, as well as the system as a whole.
- [1]
- W. Clinger, J. Rees: Revised Report on the Algorithmic Language Scheme, November 1991
- [2]
- Alfred V. Aho, Ravi Sethi, Jeffrey D. Ullman: Compilers: Principles, Techniques And Tools, Addison-Wesley, 1986
- [3]
- Andrew S. Tanenbaum: Modern Operating Systems, Prentice-Hall, 1992
- [4]
- Harold Abelsson, Gerald Sussman: The Structure and Interpretation of Computer Programs, 2nd ed. MIT-Press,1996
- [5]
- Douglas E. Comer, Internetworking with TCP/IP, Volume I, 3rd ed., Prentice Hall International, 1995
- [6]
- W. Richard, Stephens : TCP/IP Illustrated, Volume 1: The Protocols, Addison-Wesley, 1994, ISBN 0-201-63346-9.
- [7]
- Gary Wright, W. Richard Stephens: TCP/IP Illustrated, Volume 2: The Implementation, Addison-Wesley, 1995, ISBN 0-201-63354-X.
- [8]
- Robert Sedgewick: Algorithms 2nd Edition, 1988, Addison-Wesley, ISBN: 0-201-06673-4
- [9]
- Patterson, Hennessy: Computer Organization and Design. The Hardware and Software Interface, Morgan & Kaufman, 1994
- [10]
- Fred Halsall, Data Communications, Computer Networks and Open Systems, 4th ed., Addison-Wesley, 1995
- [11]
- Ravi Sethi: Programming Languages: Concepts and Constructs, Addison-Wesley 1989
- [12]
- Mark A. Weiss: Data Structures and Algorithm Analysis in C, Benjamin-Cummings, 1993.